
회의가 잘 끝났다고 느끼는 순간이 있습니다. 한 시간 동안 다섯 명이 “고객 데이터를 정비하자”, “이번 분기에 매출 정의를 맞추자” 같은 말을 주고받고, 마지막에 모두 고개를 끄덕입니다. 한 달 뒤 산출물이 모이면 이상한 일이 벌어집니다. 다섯 사람이 서로 다른 것을 만들어 왔습니다. 누가 잘못한 게 아닙니다. 같은 단어를 회의실 안에서 똑같이 발음했지만, 머릿속에서는 다섯 개의 다른 멘탈 모델이 굴러가고 있었기 때문입니다.
데이터 통합 전략(Unifying Data Strategy) 4편 시리즈의 두 번째 편이며, 정렬(Align) 단계를 다룹니다. 1편에서 잡은 어휘로 정렬되지 않은 곳을 식별했다면, 이번 편에서는 그곳을 합의로 바꿀 도구를 다룹니다.
1. 가정과 암묵지: 조직을 서서히 무너뜨리는 범인
1편에서 데이터 위생을 무너뜨리는 세 가지 위협인 모호성, 지식 격차, 맹점을 짚었습니다. 그 중에서도 정렬 단계에서 가장 자주 마주치는 위협은 모호성입니다. 모호성이란, 같은 단어가 사람마다 다른 의미로 해석되는 상태입니다. 그러나 모호성만으로는 정렬이 무너지지 않습니다. 조직의 성과가 무너지는 경우는 바로 모호성과 가정이 결합할 때입니다.
가정(assumptions)은 증명이나 검증 없이 참으로 받아들여지는 신념입니다. 회의실에서 “고객”이라는 단어가 등장했을 때, 영업 담당자는 마음속으로 “당연히 계약자를 말하는 거겠지”라고 가정합니다. CS 담당자는 “당연히 지금 제품을 쓰는 사람을 말하는 거겠지”라고 가정합니다. 두 사람 모두 자기 가정이 표준이라 믿고, 상대도 같은 가정을 한다고 다시 가정합니다. 이 이중의 가정 위에서 회의가 굴러갑니다. 합의처럼 보이는 것은 사실 가정의 충돌이 표면으로 떠오르지 않은 상태입니다.
가정이 조직을 빠르게 잠식시킬 수 있게 돕는 것이 바로 암묵지(tribal knowledge, 내부 지식)입니다. 암묵지란, 한 팀 안에서만 통하는 비공식적이고 문서화되지 않은 합의입니다. 슬랙·노션·지라·컨플루언스·구글 드라이브로 정보가 흩어질수록, 한 사람 또는 한 팀의 머릿속에만 살아 있는 정의가 늘어납니다.
가정이 회의실에 들어오는 모양은 늘 비슷합니다. 표로 정리하면 다음과 같습니다.
| 가정의 모양 | 회의실의 신호 | 결과 |
|---|---|---|
| “당연히 다 알겠지” | 핵심 어휘를 정의하지 않고 넘어감 | 사일로 안의 공통 지식이 사일로 밖에서는 미지의 영역으로 남음 |
| “분명히 그런 뜻이겠지” | 단어의 의미를 묻지 않고 끄덕임 | 같은 단어 아래 서로 다른 개념이 굴러감 |
| “전에 이렇게 했으니까” | 명시화 되지 않은 과거 의사결정을 자명한 사실로 받아들임 | 현재 맥락에 맞지 않는 정의가 새 프로젝트에 적용됨 |
| “내 정의가 표준이겠지” | 본인 부서의 정의를 전사 표준이라 가정 | 부서 간 결과물이 매번 다르게 나옴 |
정렬을 잡는 일은 이 가정들을 의식적으로 표면화시키는 일입니다. 회의를 더 오래 한다고 풀리지 않습니다. 합의된 도구로 가정을 가시화해야 풀립니다.
2. 개념 우선 설계: 당장 무언가를 만들기보다 개념을 먼저 합의하기
개념 우선 설계(Concept-first Design)는 코드나 시스템을 만들기 전에 개념을 먼저 합의하는 접근입니다. 사람들에게 평이한 언어로 본인의 비즈니스 로직과 핵심 개념을 설명하게 한 뒤, 그 설명을 구조화된 형태로 옮깁니다. 누구나 읽을 수 있을 만큼 단순하면서도, 시스템 구축의 가이드라인으로 쓸 수 있을 만큼 구조화된 형태입니다.
실무에서 개념 우선 설계는 스프레드시트 한 장으로 시작할 수 있습니다. Level 1, Level 2, Level 3로 위계를 잡고, 각 레벨에 데이터의 유형(Type)과 그 데이터가 의미하는 바인 정의(Definition)을 채웁니다. 데이터의 유형에는 Object, Number, Text, List 같은 형식이 들어갑니다. 정의에는 그 개념이 무엇을 가리키는지 누구나 읽을 수 있는 평이한 언어로 적습니다. 표로 보면 다음과 같습니다.
| Level 1 | Type | Definition | Level 2 | Type | Definition |
|---|---|---|---|---|---|
| Order | Object | 고객의 영업 주문 | |||
| Amount | Number | 주문된 상품 수량 | |||
| Price/Unit | Number | 단가 | |||
| Total | Number | 주문 총액 | |||
| SKU | Text | 상품 SKU | |||
| Sales Rep | Text | 주문을 판매한 담당자 | |||
| Revenue | Number | 매출(쟁점이 발생하는 항목) |
스프레드시트의 효과는 두 가지에서 나옵니다.
- 첫째, 머릿속에만 있던 개념이 외부에 적힌 정의로 옮겨집니다.
- 둘째, 그 정의를 두고 부서 사이에서 쟁점이 자연스럽게 떠오릅니다.
위 표에서 “Revenue”의 정의가 영업 담당자에게는 “총 판매액”, 재무 담당자에게는 “총 판매액에서 영업 담당자의 커미션을 뺀 금액”으로 갈립니다. 회의실에서 “매출 데이터를 정비하자”라고 말할 때 이 차이가 보이지 않으면, 한 달 뒤 영업과 재무가 서로 다른 매출 수치를 들고 나타납니다.
비슷한 문제 인식이 소프트웨어 설계 영역에서도 나왔습니다. 도메인 주도 설계(DDD, Domain-Driven Design)는 유비쿼터스 언어(Ubiquitous Language)라는 개념으로 도메인 전문가와 개발자가 같은 어휘를 쓰도록 합의를 만듭니다. DDD가 코드 개발 단위에서 풀려고 한 합의를, 개념 우선 설계는 비즈니스·데이터 단위로 확장합니다. 두 접근 모두 같은 출발점에 서 있습니다. 도구를 만들기 전에 어휘부터 맞추는 작업입니다.
3. 개념 나침반: 정의에 대한 차이가 있는 곳을 분류하기
개념 우선 설계가 여러가지 개념들을 한 장의 스프레드시트에 정리하는 도구라면, 개념 나침반(Concept Compass)는 하나의 정의가 어떻게 달라지고 있는지를 한 표에 펼쳐 정렬되지 않은 곳이 정확히 어디에 있는지를 파악할 수 있도록 돕는 도구입니다.
개념 나침반에는 가로축에는 핵심 이해관계자, 즉 누구(Who)가 그 개념을 다루는지가 들어갑니다. 영업·재무·IT처럼 부서가 들어가기도 하고, 한 부서 안의 역할이 들어가기도 합니다. 세로축에는 그 개념이 조직 안에서 어디(Where)에서 구현되는지가 들어갑니다. 비즈니스 로직(무엇·What), 운영(방식·Way), JSON 스키마(어떻게·How)입니다. 표의 칸에는 합의 상태를 기호로 표시합니다. 체크 표시(✓)는 합의됨, X는 의견이 다름, 물음표(?)는 모름입니다.
개념 나침반를 만드는 작업은 보통 세 단계로 굴러갑니다.
| 단계 | 묻는 질문 | 산출물 | 다음 단계로 가는 조건 |
|---|---|---|---|
| 1단계: 무엇(What) 조화 | 비즈니스 로직 차원에서 각 이해관계자가 같은 정의를 가지는가 | 부서별 개념 정의 스프레드시트 | 비즈니스 로직 합의가 만들어짐 |
| 2단계: 방식(Way) 조화 | 표명된 정의와 실제 운영 현실 사이에 차이가 있는가 | 운영 프로세스의 정렬 점검 | 표명된 방식과 실제 방식이 일치 |
| 3단계: 어떻게(How) 조화 | 비즈니스 로직이 데이터 표상으로 매끄럽게 번역되는가 | JSON Schema 등의 데이터 표상 | 비즈니스 로직과 데이터 표상이 대칭 |
1단계가 무너진 채로 2단계로 내려가면, 운영 절차는 정렬되지 않은 정의 위에 깔리므로 다시 무너집니다. 3단계도 마찬가지입니다. 무엇이 합의되지 않은 상태에서 JSON 스키마를 그려도, 그 표현은 다음 회의에서 다시 깨질 확률이 큽니다.
가상의 시나리오로 보면 윤곽이 잡힙니다. ‘이익’이라는 개념을 두고 재무·IT·영업 세 팀을 인터뷰했다고 가정해 봅시다. 표는 다음과 같이 그려집니다.

이 표는 두 방향으로 읽을 수 있습니다. 가로 방향으로 읽으면 영업 팀이 다른 두 팀과 다른 정의를 내리고 있다는 사실이 보입니다. 세로 방향으로 읽으면 비즈니스 로직 합의가 없으므로 그 아래 두 층(운영·JSON Schema)이 결정될 수 없다는 사실이 보입니다. 위 칸이 무너져 있으면 아래 칸은 자동으로 무너집니다.
4. 신념 점수와 반사실적 시나리오: “내 말이 맞다”에서 빠져나오는 두 도구
개념 나침반로 정렬되지 않은 곳이 가시화되면, 다음 질문이 따라옵니다. 어느 정의를 표준으로 잡을 것인가? 회의실에서 “내 말이 맞다”의 입장만이 오고가면 그 토론은 그저 개인들의 인격적인 싸움으로 변질됩니다. 그 싸움에서 빠져나오는 도구가 신념 점수(Belief Scoring)와 반사실적 시나리오(Counterfactuals)입니다.
1) 신념 점수
신념 점수는 한 정의에 대해 이해관계자가 가진 확신의 수준을 표시하는 도구입니다. 신념 점수는 네 가지의 척도로 이뤄집니다.
| 척도 | 의미 | 해당 정의에 대한 행동 |
|---|---|---|
| 신뢰(Trusted) ✓ | 무효화할 수 없는 관점 | 개념 나침반에 그대로 반영 |
| 불확실(Unsure) ? | 정의는 있으나 평가가 부족 | 다른 이해관계자에게 검증 요청 |
| 무효(Invalidated) X | 신뢰할 수 있는 다른 관점과 맞지 않음 | 정의를 다시 잡거나 표준에서 제외 |
| 미정의(Undefined) ~ | 정의 자체가 분명하지 않음 | 정의를 새로 작성하는 작업이 먼저 |
이렇게 척도를 통해 구분하면 두 가지 효과를 얻을 수 있습니다.
- 첫째, 개념의 불확실성을 데이터화하여 개인의 주장에 의한 싸움을 방지합니다.
“당신 말이 틀렸다”가 아니라 “이 관점은 지금 불확실 라벨이 붙어 있다”로 표현이 바뀝니다. - 둘째, 다음 단계의 작업이 명확해집니다.
불확실 라벨이 붙은 정의는 검증 작업으로, 무효 라벨이 붙은 정의는 정의 재작성 작업으로, 미정의 라벨이 붙은 항목은 새 정의 작성 작업으로 흐릅니다.
2) 반사실적 시나리오
“만약 이 정의가 틀렸다면 어떤 결과가 나올까?”
반사실적 시나리오는 위와 같은 질문으로 정의를 흔들어 봅니다. 예를 들어 이해관계자가 “주문 상태를 실시간으로 조회할 수 있어야 한다”고 요건을 제시했다고 해 봅시다. 여기서 반사실적 질문을 던집니다. “실시간이 아니라 1시간 간격으로 갱신해도 괜찮을까요?” 답이 바로 안 나오면, “실시간”이라는 조건이 정말 핵심인지 재검토할 여지가 생깁니다. 반대로 “그러면 고객 문의가 폭주합니다”처럼 답이 명확하면, 그 답 자체가 요건의 근거가 됩니다.
같은 방식으로 “할인율에 100%가 들어오면?”, “배송지 주소가 비어 있으면?” 같은 질문도 가능합니다. 이런 질문들이 정의에서 빠진 예외 조건이나 유효성 규칙을 자연스럽게 떠올리게 해 줍니다.
5. 네 가지 조직 운영 함정: 도구가 있어도 정렬이 막히는 경우
앞서 살펴본 도구를 다 갖추고도 정렬이 안 되는 경우가 있습니다. 도구의 문제가 아니라 조직 운영 패턴 자체가 걸림돌일 때입니다. 이런 패턴을 무지, 사일로화된 인센티브, 근시안, 우유부단 네 가지로 나눠 볼 수 있습니다.
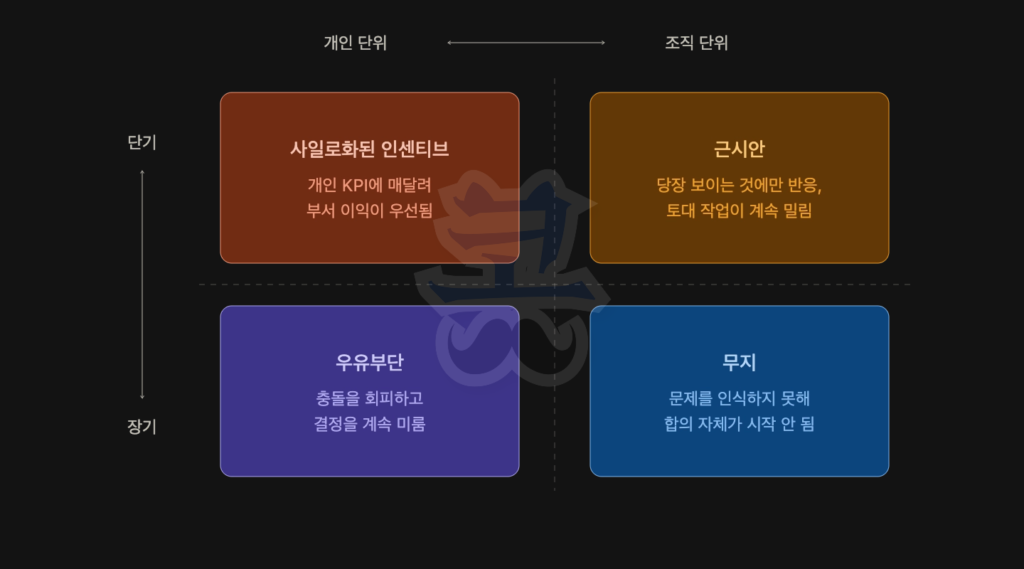
| 패턴 | 실무에서 보이는 모습 | 왜 정렬을 막는가 | 풀어 가는 방향 |
|---|---|---|---|
| 무지(Ignorance) | “우리 팀은 데이터 잘 쓰고 있는데?”라는 근거 없는 자신감 | 리더가 문제가 되는 곳을 인식 못 하면 기본 개념부터 합의가 안 됨 | 리더 본인이 학습에 시간을 들이고, 모르는 영역을 인정 |
| 사일로화된 인센티브(Siloed Incentives) | 분기 KPI 보너스에만 매달림 | 개인 지표가 조직 목표와 어긋나면 합의보다 부서 이익이 우선됨 | 인센티브 설계를 전사적인 목표에 재정렬 |
| 근시안(Shortsightedness) | 끊임없이 당장 앞에 보이는 것에만 집중하는 반응적인 운영 | 단기 성과가 눈에 보이니 장기 토대 작업이 계속 밀림 | 근본 원인을 짚는 작업에 명시적으로 시간 배정 |
| 우유부단(Indecisiveness) | 충돌 회피, 결정 미루기 | 매니저가 갈등을 곪게 두면 합의 없이 회의만 반복됨 | 결정을 내리거나, 확신이 없으면 결정 권한을 명확히 위임 |
어느 칸에 막혀 있는지 식별하면, 풀어야 할 레이어가 달라집니다.
6. 정렬은 단발성이 아닌 반복적인 과정
여기까지 정리한 도구들이 모이면, 정렬은 일회성 회의가 아니라 반복 가능한 절차로 돌아갑니다.
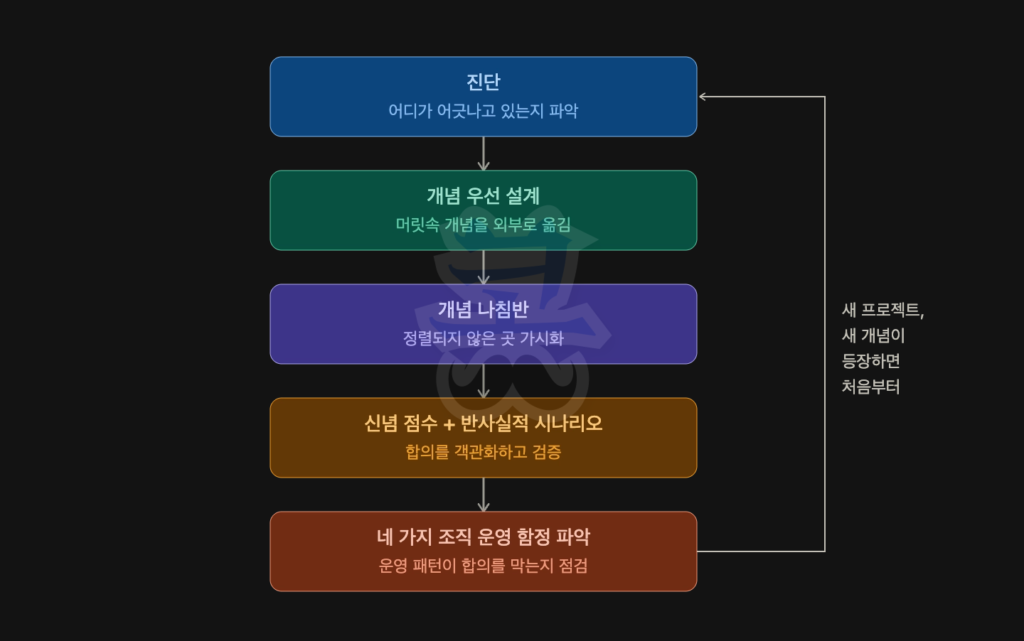
비즈니스 환경이 바뀌면 정렬도 흔들립니다. 새 시장이 열리거나, 새 시스템이 들어오거나, 핵심 인력이 바뀌거나. 어느 하나만 바뀌어도 한번 잡힌 합의가 다시 느슨해집니다. 정렬이 잘 작동하고 있는지 확인하는 가장 간단한 신호는 새로 합류한 사람입니다. 그 사람이 합의된 정의를 빠르게 흡수해서 바로 업무에 쓸 수 있으면 정렬이 살아 있는 겁니다. 반대로 며칠이 지나도 정의를 못 찾아서 본인 추측으로 빈칸을 메우기 시작한다면, 모호성이 다시 스며들고 있다는 뜻입니다.
마무리
2편에서 다룬 도구를 정리하면 다음과 같습니다.
개념 우선 설계로 머릿속 개념을 꺼내 정의로 만들고, 개념 나침반으로 정의가 어긋난 곳을 찾고, 신념 점수와 반사실적 시나리오로 어떤 정의를 표준으로 삼을지 검증합니다. 이 과정에서 도구가 아니라 조직 운영 패턴이 막고 있다면, 네 가지 안티패턴(무지, 사일로화된 인센티브, 근시안, 우유부단)을 점검합니다.
정렬은 의지의 문제가 아닙니다. 도구 없이 회의만 반복하면 가정의 충돌은 수면 아래 남고, 한 달 뒤 산출물에서야 합의가 없었다는 사실이 드러납니다.
3편에서는 합의된 정의를 독립적으로 쓸 수 있는 단위로 패키징하는 방법을 다룹니다. 데이터 프로덕트(Data Product)라는 개념에 기반해, 데이터, 구조, 의미, 맥락이 어떻게 하나로 묶이는지를 살펴봅니다.
통합 데이터 전략 시리즈
(1) ‘진단’: 우리 조직은 어디가 정렬되지 않았는가