
광고비 1억을 썼더니 매출이 5억 나왔습니다. 이 한 문장 뒤에는 무수한 인프라가 숨어 있습니다. 어떤 비용 모델로 돈을 냈는지, 어떤 지표로 성과를 봤는지, 그 매출을 어느 광고에 매겼는지, 그 결과를 누가 측정했는지, 그 측정 자체는 다시 누가 검증했는지. 광고 산업의 절반은 사실 “검증”을 둘러싼 인프라입니다.
7편은 광고가 노출되고 클릭되고 전환된 이후의 세계, 광고가 “돈 값”을 했는지를 따지는 자리를 다룹니다. 분량이 두꺼워 세 편으로 나눠 풀어가려 합니다. 첫 편인 7-1은 측정의 가장 안쪽 자리, “광고비를 어떤 단위로 매기고, 그 결과 발생한 매출을 어느 광고에 매기는가”를 다룹니다.
1. 비용 모델: 무엇에 돈을 내는가
광고비는 한 가지 방식으로 매겨지지 않습니다. 노출에 내느냐, 클릭에 내느냐, 행동에 내느냐에 따라 비용 모델이 갈리고, 그 선택이 캠페인 목적과 직결됩니다.
| 모델 | 풀이 | 한 줄 정의 | 적합 캠페인 |
|---|---|---|---|
| CPM | Cost Per Mille | 노출 1,000회당 비용 | 인지도(Awareness) |
| CPC | Cost Per Click | 클릭 1회당 비용 | 트래픽(Traffic) |
| CPA | Cost Per Action | 전환 1회당 비용 | 매출·전환(Sales), 잠재 고객(Leads) |
| CPI | Cost Per Install | 앱 설치 1회당 비용 | 앱 프로모션(App Promotion) |
| CPV | Cost Per View | 비디오 시청 1회당 비용 | 참여(Engagement) |
| CPL | Cost Per Lead | 리드 1건당 비용 | 잠재 고객(Leads) |
| CPCV | Cost Per Completed View | 비디오 완료 시청 1회당 비용 | 참여(Engagement, 완주율 중심) |
같은 광고 한 번을 두고도 “노출됐다”, “클릭됐다”, “전환됐다”는 사건은 모두 다른 단위입니다. 광고주는 이 중 어느 단위에 자기 비용을 걸지 정해야 합니다.
같은 슬롯에 노출 100,000회가 발생한다고 가정하고, CPM 1,000원과 CPA 10,000원으로 사는 두 경우의 광고주 부담을 비교해보겠습니다.
| 전환 결과 | CPM 1,000원 (광고주 부담) | CPA 10,000원 (광고주 부담) |
|---|---|---|
| 전환 0건 | 100,000원 | 0원 |
| 전환 10건 | 100,000원 | 100,000원 |
| 전환 50건 | 100,000원 | 500,000원 |
| 위험 부담 주체 | 광고주 | 매체사 |
CPM은 광고주가 노출 수에만 비용을 거니 효과가 0건이어도 그대로 청구됩니다. CPA는 전환이 일어났을 때만 청구되니 효과 없으면 0원, 잘 맞으면 광고주가 더 많이 냅니다. 매체사는 CPA에서 “전환이 안 일어날 위험”을 떠안기 때문에, 같은 슬롯이라도 CPA 단가는 CPM 단가보다 위험 프리미엄만큼 비쌉니다.
1) eCPM
이 위험 차이가 매체사의 내부 경매에서 어떻게 처리되는지 보면 모델 간 관계가 더 분명해집니다. 매체사는 같은 슬롯을 두고 CPM·CPC·CPA 입찰자를 동시에 받는데, 이 셋을 한 자리에서 비교하기 위해 모두 노출 1,000회 기준 효과 비용으로 환산합니다. 이 환산값이 eCPM(effective CPM)입니다.
| 입찰 모델 | 단가 | 노출 1,000회당 발생 | 환산 eCPM |
|---|---|---|---|
| CPM | 1,000원 / 노출 1,000회 | (그 자체) | 1,000원 |
| CPC | 1,000원 / 클릭 | 클릭 10회 (CTR 1%) | 10,000원 |
| CPI | 5,000원 / 설치 | 설치 5회 (설치율 0.5%) | 25,000원 |
매체사는 이 값이 가장 높은 입찰자에게 슬롯을 내줍니다. 그래서 CPC로 사면 클릭이 잘 일어날 자리에, CPA로 사면 전환이 잘 일어날 자리에 광고가 배분되는 구조가 자연스럽게 만들어집니다.
eCPM은 매체사 입장의 지표이지만, 광고주도 매체 간 인벤토리 가격을 비교하려면 eCPM을 알아야 합니다. 3편에서 본 인벤토리 가치를 매기는 핵심 지표가 결국 eCPM입니다.
2) vCPM
또 하나 중요한 변형이 vCPM(viewable CPM)입니다. 3편에서 본 가시성(viewability) 표준(MRC 기준 디스플레이는 픽셀의 50%가 1초 이상, 비디오는 50%가 2초 이상 화면에 보여야 충족)을 만족한 노출만 비용 산정에 포함합니다. 노출 100,000회 중 50,000회만 가시성 기준을 채웠다면 광고주는 50,000회분만 지불합니다. 화면 밖에서 자동 발생한 노출에 돈을 내고 싶지 않다는 요구가 vCPM으로 제도화된 자리입니다.
한국 광고주의 운용 관행은 매체별 분리가 더 강합니다. 네이버 GFA는 CPM·CPC, 카카오 모먼트는 CPM·CPC·CPA를 운영하지만, 광고주는 디스플레이는 CPM, 검색은 CPC, 앱은 CPI·CPA로 나눠 사는 게 보통입니다. 한 캠페인 안에서 매체별 비용 모델이 다른 게 일반적이라, 통합 보고가 한국에서 더 까다로워집니다.
2. 성과 지표: 무엇을 보고 캠페인을 평가하는가
비용 모델이 “무엇에 돈을 내는가”라면, 성과 지표는 “무엇을 보고 잘했다·못했다를 판단할까”입니다. 퍼널(funnel) 단계마다 봐야 할 지표가 다릅니다.
| 카테고리 | 지표 | 계산식 | 단위 |
|---|---|---|---|
| 노출·도달 | 노출 수(Impressions) | 노출 발생 합계 | 회 |
| 노출·도달 | 도달(Reach) | 중복 제거된 사용자 수 | 명 |
| 노출·도달 | 빈도(Frequency) | 노출 수 ÷ 도달 | 회/명 |
| 참여 | 클릭률(CTR, Click-through Rate) | (클릭 ÷ 노출) × 100 | % |
| 참여 | 시청 완료율(VTR, View-through Rate) | (완료 시청 ÷ 시작) × 100 | % |
| 전환 | 전환율(CVR, Conversion Rate) | (전환 ÷ 클릭) × 100 (또는 전환 ÷ 노출 × 100) | % |
| 전환 | 광고비 대비 매출(ROAS, Return on Ad Spend) | 매출 ÷ 광고비 | 배수 / % |
| 전환 | 투자 대비 수익(ROI, Return on Investment) | (순수익 ÷ 광고비) × 100 | % |
| 사용자 가치 | 고객 생애 가치(LTV, Lifetime Value) | ARPU × 평균 사용자 수명 × 마진율 | 통화 |
| 사용자 가치 | LTV/CAC 비율 | LTV ÷ CAC | 배수 / % |
| 사용자 가치 | 잔존율(Retention) | (t기간 후 활동 사용자 ÷ 초기 사용자) × 100 | % |
| 가시성·품질 | 가시성 충족률(Viewability Rate) | (가시성 충족 노출 ÷ 총 노출) × 100 | % |
처음 보는 사람한테 광고가 도달했는지(Reach), 그 사람이 광고에 반응했는지(CTR), 반응한 사람이 행동했는지(CVR), 행동한 사람이 돈을 가져왔는지(ROAS), 그 사람이 한 번이 아닌 여러 번 돈을 가져올지(LTV)까지가 한 줄로 이어집니다.
1) ROAS와 ROI: 같은 캠페인, 다른 결론
광고비 1,000만 원을 써서 매출 3,000만 원이 났다고 가정합니다. 마진율 30% 비즈니스라면 두 지표의 결과는 다른 방향을 가리킵니다.
| 지표 | 산식 | 계산 결과 | 해석 |
|---|---|---|---|
| ROAS | 3,000만 / 1,000만 | 3.0x | 매출 회수 3배, 좋아 보임 |
| ROI | (3,000만 × 0.3 − 1,000만) / 1,000만 | −10% | 마진 회수 적자 |
마진율이 낮을수록 두 지표의 격차는 커집니다. ROAS는 매출을 기준으로 광고 효율을 판단하는 지표이고, ROI는 광고비를 포함한 실제 이익 기준으로 판단하는 지표입니다.
이 때문에 ROAS만 보면 성과가 좋아 보이더라도, 마진을 고려하면 손익 기준에서는 적자가 발생할 수 있습니다. 즉, ROAS는 “얼마를 벌어왔는가”를, ROI는 “실제로 남았는가”를 보는 지표입니다.
2) LTV와 LTV/CAC 비율
LTV는 평균값으로만 보면 채널별 차이를 놓칩니다. 코호트 분석(cohort analysis)으로 가입 시점·획득 채널별로 그룹을 나눠 추적해야 정확해집니다. 검색 광고로 들어온 사용자는 빠르게 결제하고 빠르게 떠나고, 콘텐츠 광고로 들어온 사용자는 느리게 결제하지만 오래 남는 식의 패턴이 LTV의 채널별 격차로 보입니다.
LTV를 사용자 획득 비용(CAC, Customer Acquisition Cost)으로 나눈 LTV/CAC 비율이 광고비 의사결정의 사실상 기준 지표입니다.
| LTV/CAC | 의미 |
|---|---|
| < 1.0x | 적자, 광고비 회수 불가 |
| 1.0x ~ 3.0x | 회수 구간 |
| ≈ 3.0x | 산업 기준, 이상적 |
| > 5.0x | 과소투자, 성장 기회 손실 가능 |
서비스형 소프트웨어(SaaS, Software as a Service)·구독 비즈니스가 광고비 결정에 일상적으로 쓰는 숫자입니다.
3) 빈도(Frequency)와 빈도 캡
빈도는 사용자당 평균 노출 횟수이고, 빈도 캡(Frequency cap)은 한 사용자에게 허용하는 최대 노출 횟수의 운영 결정값입니다. 효과적 빈도(Effective frequency)는 인지가 일어나는 최소 노출 횟수로, 보통 3~5회로 잡습니다.
| 빈도 구간 | 결과 |
|---|---|
| 1~2회 | 인지 안 잡힘, 광고비 새는 자리 |
| 3~5회 | 효과적 빈도, 인지·고려 형성 |
| 6~9회 | 전환 압박, ROAS 정점 부근 |
| 10회 이상 | 광고 피로, 효율 급감 + 부정 인식 위험 |
빈도 캡을 어디에 두느냐가 ROAS와 LTV에 동시에 영향을 줍니다. 너무 좁게 잡으면(예: 사용자당 2회) 한 사람당 노출이 인지 임계값(3~5회)에 못 미쳐 전환이 일어나지 않습니다. 위 표의 1~2회 구간이 이 자리이고, 도달은 했는데 전환이 따라오지 않으니 ROAS가 깎이고, 약한 인지로 들어온 사용자는 잔존도 짧아 LTV까지 함께 줄어듭니다.
반대로 너무 풀어두면(예: 사용자당 15회) 신규 사용자 도달은 멈춘 자리에 같은 사람에게만 광고가 계속 쌓입니다. 추가 노출이 전환을 만들지 못한 채 광고비만 소진되니 ROAS가 떨어지고, 광고 피로가 누적된 사용자가 브랜드를 떠나면 LTV에도 부정 영향이 갑니다.
한 가지 주의할 자리는 캡 설정이 캠페인 단계마다 비대칭이라는 점입니다. 사용자가 광고를 처음 만나는 인지 캠페인은 시작 빈도가 0이라 캡을 넉넉하게(주 5~10회) 풀어 효과적 빈도(3~5회)까지 누적될 여지를 줘야 합니다. 반대로 리타게팅·전환 캠페인의 사용자는 다른 광고로 이미 누적 노출이 쌓여 있어, 캡을 같은 폭으로 풀면 위 표의 10회 이상 구간으로 빠르게 넘어가 피로가 폭주합니다. 그래서 리타게팅·전환은 캡을 좁게(주 2~3회) 잡아 총 누적 빈도가 ROAS 정점 구간(6~9회) 안에 머물도록 운영합니다.
3. 어트리뷰션(Attribution): 누구의 공인가
광고가 사용자에게 보이고, 클릭됐고, 전환이 일어났습니다. 그런데 그 사용자는 그날 광고를 한 개만 본 게 아닙니다. 디스플레이로 한 번, 검색으로 한 번, SNS로 한 번을 보고 결국 구매했습니다. 그 매출을 어느 광고에 귀속시킬 것인가. 이게 어트리뷰션이고, 단순한 질문 같지만 광고 산업에서 가장 어려운 문제 중 하나입니다.
1) 어트리뷰션 모델 개괄
다음 사용자 여정을 가정해보겠습니다. 30일 사이에 세 채널을 거쳐 구매가 일어난 자리입니다.

같은 매출 100,000원을 6개 모델이 각각 어떻게 분배하는지가 어트리뷰션 모델의 차이입니다.
| 계열 | 모델 | 분배 방식 | SNS (Day 1) | 디스플레이 (Day 14) | 검색 (Day 30) |
|---|---|---|---|---|---|
| 싱글 터치 | 라스트 클릭(Last-click) | 마지막 접점에 100% | 0원 | 0원 | 100,000원 |
| 싱글 터치 | 퍼스트 클릭(First-click) | 첫 접점에 100% | 100,000원 | 0원 | 0원 |
| 멀티 터치 | 리니어(Linear) | 모든 접점에 균등 분배 | 33,333원 | 33,333원 | 33,333원 |
| 멀티 터치 | 타임 디케이(Time-decay) | 전환에 가까울수록 가중치 상승 (반감기 보통 7일) | ~10,000원 | ~30,000원 | ~60,000원 |
| 멀티 터치 | 포지션 베이스드(Position-based) | 첫·마지막에 각 40%, 중간 접점 합 20% (U자형) | 40,000원 | 20,000원 | 40,000원 |
| 멀티 터치 | 데이터 드리븐(Data-driven) | 머신러닝이 실제 사용자 여정 데이터로 학습해 분배 | 예: 25,000원 | 예: 30,000원 | 예: 45,000원 |
라스트 클릭, 퍼스트 클릭은 한 접점에 100%를 몰아주는 싱글 터치(Single-touch)이고, 아래 네 모델은 여러 접점에 기여도를 분배하는 멀티 터치 어트리뷰션(MTA, Multi-touch Attribution) 계열입니다. 라스트 클릭이 광고 업계의 오랜 기본값이었지만, 첫 두 접점에 0원을 매기는 방식이 도입·고려 단계 광고를 무료 봉사로 만든다는 한계가 명확해 시장이 MTA, 그중에서도 데이터 드리븐 쪽으로 옮겨갔습니다.
GA4는 2021년 11월 1일부터 신규 속성에 데이터 드리븐을 기본값으로 적용했고, 구글 애즈도 2023년 신규 전환 액션 기본값을 데이터 드리븐으로 전환했습니다. 다만 데이터 드리븐 표준화는 구글 생태계가 가장 빠르고, 메타·틱톡·링크드인의 매체 자체 보고는 아직 라스트 클릭 디폴트를 유지합니다. 4.1에서 다룰 모바일 MMP 환경도 별개의 자리이고, 거기서는 라스트 클릭이 사실상 디폴트로 남아 있습니다. 데이터 드리븐이 광고 측정의 큰 방향인 건 분명하지만, 영역마다 속도가 다른 게 2026년 현재의 모습입니다.
MTA의 문제
문제는 MTA가 교차 사이트(cross-site) 추적을 전제로 한다는 점입니다. 사용자가 SNS·디스플레이·검색에 걸쳐 같은 사람이라는 것을 잇는 ID가 있어야 가능한데, 5편에서 본 쿠키 차단·iOS의 앱 추적 투명성(ATT, App Tracking Transparency) 이후로 데스크톱 웹에서는 이 ID가 끊겼습니다.
다만 모바일은 사정이 다릅니다. 모바일은 소프트웨어 개발 키트(SDK, Software Development Kit)가 디바이스 단위 식별자(Android의 광고 식별자 GAID, iOS의 광고 식별자 IDFA)로 결정론적 매칭(deterministic matching)을 하기 때문에, 모바일 측정 파트너(MMP, Mobile Measurement Partner)라는 형태의 MTA가 여전히 작동합니다. MTA가 좁아진 자리는 데스크톱 웹이고, 모바일은 별개의 환경입니다.
2) 데이터 기반 어트리뷰션 작동 원리: 마르코프 체인과 섀플리 값
데이터 기반 어트리뷰션(DDA, Data-driven Attribution)은 표에 한 줄로 적었지만 실제로는 두 가지 통계 기법 위에서 돌아갑니다. 마르코프 체인(Markov chain)과 섀플리 값(Shapley value)입니다.
마르코프 체인은 확률적 사고로 풉니다. 사용자 여정의 각 채널을 상태(state)로 보고, 한 채널을 통째로 제거했을 때 전환이 얼마나 떨어지는지(removal effect)를 측정합니다.
| 채널 | 제거 시 전환 감소 예시 | 상대 기여도 |
|---|---|---|
| SNS | −30% | 30 |
| 디스플레이 | −20% | 20 |
| 검색 | −50% | 50 |
| 합계 | 100 |
섀플리 값은 게임 이론에서 빌려온 원리를 적용합니다. n개 채널의 가능한 모든 순서·조합(2의 n승개)을 평가해 각 채널의 한계 기여도를 평균 냅니다. “공평한 분배”를 보장하지만 채널 수가 많아질수록 계산해야할 값들이 폭발합니다.
| 채널 수 (n) | 평가할 조합 수 (2^n) |
|---|---|
| 4 | 16 |
| 10 | 1,024 |
| 15 | 32,768 |
| 20 | 1,048,576 |
GA4의 DDA는 섀플리 값 기반에 시간 가중치를 더해 최대 50개 접점까지 처리합니다. 데이터 요건은 30일 내 해당 전환 액션 400건, 그리고 룩백 윈도우 안 전체 전환 20,000건입니다. 이 기준에 미달하면 GA4는 조용히 라스트 클릭으로 되돌아가는데, 광고주가 알지 못한 채로 운영되는 경우가 많아 DDA를 쓴다고 해서 항상 데이터 기반으로 작동하는 건 아닙니다.
3) 어트리뷰션 윈도우: 며칠을 잡을 것인가
같은 어트리뷰션 모델 안에서도 “전환을 며칠 안에 잡을지”가 또 다른 결정입니다. 6편에서 본 기여 기간(Lookback Window)은 매체별 디폴트와 광고주가 풀 수 있는 범위가 다릅니다. 산업의 사실상 디폴트는 클릭 7일·뷰 1일입니다.
| 매체 | 클릭 기여 윈도우 디폴트 | 뷰 기여 윈도우 디폴트 |
|---|---|---|
| 메타 | 7일 | 1일 (2026년 1월부터) |
| 구글 애즈 | 30일 (검색·쇼핑 기준, 1~30일 또는 60·90일 선택 가능) | 1일 |
| 틱톡 | 7일 (1·7·28일 중 선택) | 1일 |
| 링크드인 | 30일 | 7일 |
(1) 윈도우 × 모델의 상호작용
같은 30일 윈도우라도 어트리뷰션 모델이 라스트 클릭이냐 데이터 드리븐이냐에 따라 “잡힌 전환”이 다른 광고에 귀속됩니다. 라스트 클릭 + 30일 윈도우는 30일 안의 마지막 클릭에 100%를 매기니 후반부 매체(검색·리타게팅)가 모든 공을 가져가고, 데이터 드리븐 + 30일 윈도우는 같은 30일 안의 모든 접점에 머신러닝 가중치로 분배합니다. 전환 숫자는 같아도 채널별 ROAS는 30~50%까지 다르게 보고됩니다. 윈도우 결정이 채널 예산 배분 결정으로 곧장 이어지는 자리입니다.
(2) 매체 간 윈도우 불일치 → 같은 전환의 중복 보고
광고주가 메타·구글·틱톡을 동시에 운영할 때, 각 매체의 윈도우 디폴트가 다르면 같은 한 건의 전환을 셋이 동시에 자기 공으로 보고하는 일이 일어납니다. 사용자가 메타 광고를 보고 1일 안에 구글 검색으로 사이트에 들어와 다시 30일 안에 결제하면, 메타는 1일 뷰 윈도우 안의 전환으로 잡고 구글은 30일 클릭 윈도우 안의 전환으로 잡습니다. 두 매체가 한 매출을 각자 자기 공으로 가져가니, 광고주가 보고서를 합산하면 실제 매출의 1.5~2배가 잡힙니다. MMP·MMM 같은 중립 측정 도구가 필요한 결정적인 자리이고, 6편에서 본 자기 평가(Self-attribution) 문제가 윈도우 차원에서 다시 등장하는 자리이기도 합니다.
(3) 매체의 윈도우 변경이 측정 자체를 흔든다
2026년 1월 12일 메타가 애즈 인사이트 API(Ads Insights API)에서 7일 뷰·28일 뷰 윈도우를 영구 제거하면서, 같은 캠페인의 보고된 전환 숫자가 광고주별로 30~40% 떨어졌습니다. 실제 캠페인 성과는 변하지 않았는데 보고 숫자만 줄어든 셈입니다. 이 변경 이후 광고주는 “ROAS가 떨어졌으니 메타 예산을 줄여야 하나”라는 잘못된 결론에 빠지기 쉽습니다. 매체의 측정 정책 변경 한 번이 광고주의 채널 예산 결정으로 번지는 자리입니다.
iOS의 SKAN은 이 윈도우 결정 권한을 매체사가 아니라 OS가 강제하는 새로운 패러다임입니다. 광고주가 윈도우를 못 바꾸고, OS가 정해준 0~2일·3~7일·8~35일 세 구간 안에서만 측정합니다.
4) 어트리뷰션의 근본 한계
어트리뷰션이 측정하는 건 “상관관계”이지 “인과관계”가 아닙니다. 광고를 봤고 샀다는 사실이, 광고 때문에 샀다는 뜻은 아닙니다. 그 사람은 광고를 안 봤어도 어차피 살 사람이었을 수도 있습니다. 이 질문에 답하려면 어트리뷰션이 아니라 7번 섹션의 증분 효과(Incrementality) 측정이 필요합니다. 어트리뷰션은 “공이 누구 거냐”에는 답하지만 “공이 진짜로 있었냐”에는 답하지 않습니다.
4. MMP: 모바일 광고의 공정 심판
모바일 앱 광고는 자체 폐쇄형 플랫폼(Walled Garden)들이 자기 광고만 측정하겠다고 주장하는 환경입니다. 구글·메타·틱톡·애플 모두 자기네 광고가 가장 효과적이었다고 보고하고, 같은 광고비를 셋이 동시에 자기 공으로 가져갑니다. 그래서 광고주에게는 중립적인 측정자가 필요해졌습니다. 그게 앞서 잠깐 짚은 모바일 측정 파트너(MMP)입니다.
1) 모바일 측정 파트너(MMP, Mobile Measurement Partner)의 매칭 방법
MMP는 광고 클릭과 앱 설치를 한 사용자의 행동으로 잇는 일을 합니다. 매칭 방식은 두 가지가 있습니다.
| 구분 | 결정론적 매칭(Deterministic Matching) | 확률론적 매칭(Probabilistic Matching, Fingerprinting) |
|---|---|---|
| 개념 | 디바이스 고유 식별자로 클릭과 설치를 직접 일치 | 메타데이터를 기반으로 동일 사용자일 가능성을 추정 |
| 사용 식별자 | GAID(Google Advertising ID), IDFA(Identifier for Advertisers) | IP 주소, User-Agent, 디바이스 모델, 해상도, 시각, 통신사 등 |
| 정확도 | 매우 높음 (사실상 100%) | 중간 수준 (약 70~90%) |
| 사용 조건 | 광고 ID가 존재하고 추적 가능할 때 | 광고 ID가 없거나 사용 불가할 때 (폴백) |
| 장점 | 높은 신뢰도, 명확한 사용자 매칭 | 광고 ID 없이도 일부 매칭 가능 |
| 한계 | ATT 미동의, ID 초기화 시 사용 불가 | 정확도 낮음, 프라이버시 규제 영향 큼 |
| 정책 환경 | 기본 표준 방식 | iOS에서 정책적으로 제한/금지 추세 |
(1) 결정론적 매칭 (Deterministic Matching)
결정론적 매칭은 같은 GAID(Google Advertising ID)·IDFA(Identifier for Advertisers)가 클릭 시점과 첫 실행 시점에 일치하면 MMP가 둘을 한 사용자의 행동으로 100% 신뢰하고 매핑하는 방식입니다. 안드로이드는 구글 플레이 서비스가 GAID를 거의 모든 사용자에게 자동 노출하니 결정론적 매칭이 항상 작동하고, iOS는 사용자가 ATT(App Tracking Transparency, 앱 추적 투명성) 동의를 한 디바이스에 한해 IDFA가 노출됩니다.
(2) 확률론적 매칭 (Probabilistic Matching, Fingerprinting)
iOS에서 사용자가 ATT 동의를 거부해 IDFA가 없거나, 사용자가 광고 ID를 초기화한 경우처럼 결정론적 매칭이 불가능한 자리에 쓰는 폴백(Fallback, 대체안)입니다. IP 주소, User-Agent(브라우저·OS 버전), 디바이스 모델, 화면 해상도, 시각, 통신사 같은 메타데이터를 묶어 클릭과 설치를 통계적으로 같은 사용자라고 추정합니다. 정확도가 결정론적 매칭의 70~90% 수준에 그치고, 애플은 2022년 이후 iOS에서 핑거프린팅(fingerprinting, 기기 정보 기반 식별)을 정책적으로 금지하고 있어 모바일 어트리뷰션의 무게중심은 결정론적 매칭 + SKAN(4.3)으로 옮겨가는 추세입니다.
2) 매칭 + 기여 윈도우 + 어트리뷰션 모델 예시
매칭만으로는 어트리뷰션이 끝나지 않습니다. 한 사용자가 7일 동안 메타·구글·틱톡 광고를 모두 클릭한 뒤 설치했다면, 매칭으로 세 건이 같은 사용자의 행동인 것까지는 확인되지만, 어느 클릭에 공을 매길지는 어트리뷰션 모델이 결정합니다. MMP의 디폴트 모델은 3.1에서 본 라스트 클릭이고, 디폴트 라이트백 윈도우는 7일입니다. 윈도우 안의 마지막 클릭에 100%를 매기고, 그 앞의 클릭들은 0원으로 처리합니다.

윈도우 안에 어떤 클릭도 발견되지 않으면, MMP는 그 설치를 “오가닉(Organic)”으로 분류합니다. 광고 없이 자연 발생한 설치라는 뜻이고, 광고비가 매겨지지 않습니다. 광고주의 운영 자리에서 오가닉 비율은 광고 채널의 진짜 기여도를 가늠하는 보조 지표로 쓰입니다.
이 예시의 한계는 디폴트가 라스트 클릭이라는 점에 있습니다. MMP가 데이터 드리븐·멀티 터치 옵션을 추가로 제공하지만, 모바일 업계에서는 라스트 클릭이 사실상 표준으로 굳어 있어, 도입·고려 단계 광고가 무료 봉사로 처리되는 한계가 모바일에도 그대로 들어와 있습니다.
3) 라스트 클릭에 머물게 되는 이유
앞에서 본 구글 생태계는 데이터 드리븐으로 빠르게 옮겨가고 있는데, MMP만 라스트 클릭에 머무는 데는 두 가지 구조적 이유가 있습니다.
| 이유 | 설명 |
|---|---|
| iOS SKAN 구조 | OS(애플)가 어트리뷰션을 직접 결정하고 단일 매체에만 결과를 전달하므로, MMP가 다중 접점 데이터를 확보·분배할 수 없음 |
| 안드로이드 데이터 드리븐 불일치 | MMP마다 서로 다른 모델을 사용해 결과가 일관되지 않으며, 매체사 간 신뢰 기준 부재 |
| 데이터 부족 | 데이터 드리븐 모델 학습에 필요한 충분한 전환량(월 수천 건)을 확보하지 못하는 광고주가 많음 |
| 중립 측정자로서의 제약 | MMP는 광고주와 매체사 사이의 중립적 위치이므로, 분쟁을 피하기 위해 검증 가능하고 단순한 라스트 클릭을 기본값으로 채택 |
| 블랙박스 문제 | 데이터 드리븐 모델은 내부 로직이 불투명해 매체사가 결과를 신뢰하기 어렵고, 분쟁 발생 가능성 높음 |
첫째, iOS의 SKAN(뒤에서 다룸)은 OS가 어트리뷰션을 직접 결정합니다. 사용자가 메타·구글·틱톡 광고를 모두 봤더라도, 애플이 자체 알고리즘으로 마지막 한 매체사를 골라 그 매체사에게만 어트리뷰션 결과(postback)를 보냅니다. MMP는 애플이 이미 결정해서 보낸 결과를 받아 광고주에게 전달할 뿐이라, 여러 접점에 기여를 분배하고 싶어도 분배할 원본 데이터 자체가 OS 단계에서 차단된 자리입니다.
둘째, 안드로이드의 결정론적 매칭 환경에서는 MMP들이 데이터 드리븐 옵션을 제공합니다. 다만 각 MMP가 자체 머신러닝 모델을 쓰니 광고주가 앱스플라이어로 본 결과와 애드저스트로 본 결과가 다르게 나옵니다. 한쪽은 메타가 ROAS 3배라고 하는데 다른 쪽은 1.5배라고 하는 식입니다. 매체사도 어느 MMP의 모델을 신뢰해야 할지 합의가 잡혀 있지 않습니다. 거기에 데이터 드리븐 학습에 필요한 전환 건수(보통 월 수천 건)를 채우는 앱 광고주가 많지 않아 도입이 더 더딥니다.
이 두 자리의 바탕에는 MMP가 광고주와 매체사 사이의 중립 측정자라는 본질이 있습니다. 어떤 매체사도 자기 광고에 불리한 측정 결과를 그냥 받아들이지 않으니, MMP는 모든 매체사가 검증할 수 있는 투명하고 단순한 규칙, 즉 라스트 클릭을 디폴트로 가져가야 분쟁이 안 생깁니다. 복잡한 머신러닝 분배는 매체사 입장에서는 블랙박스라 “왜 우리 광고에 더 적게 매겼냐”는 항의의 원천이 됩니다. 그래서 모바일 어트리뷰션 자리에서는 데이터 드리븐이 기술적으로는 가능해도 사회적으로는 자리 잡지 못한 상태가 이어지고 있습니다.
4) 주요 MMP
| MMP | 강점 | 비고 |
|---|---|---|
| 앱스플라이어(AppsFlyer) | 글로벌 점유율 1위 (Statista 기준 Android 어트리뷰션 SDK의 약 47%, iOS의 약 40%) | 한국에서도 사실상 표준 |
| 애드저스트(Adjust) | 모바일 게임 강세, 실시간 사기 방지(fraud prevention) | 2021년 4월 애플로빈(AppLovin)이 인수 (약 9.8억 달러 규모) |
| 싱귤러(Singular) | 광고비와 어트리뷰션을 한 플랫폼에 통합 | ROI 분석 강점 |
| 브랜치(Branch) | 딥링크와 어트리뷰션 통합 | 웹투앱 어트리뷰션 강점 |
| 에어브릿지(Airbridge) | 한국 본사, 한국 데이터 서버 | 네이버·카카오 검색·디스플레이 비용 연동을 모두 지원하는 국내 유일 MMP |
앱스플라이어의 글로벌 우위가 한국에도 그대로 반영되지만, 에어브릿지가 국내 매체 통합 측정의 차별점으로 의미 있는 입지를 확보하고 있습니다.
5. SKAN과 AAK: iOS와 안드로이드가 갈리는 지점
iOS의 ATT 정책으로 IDFA 동의율이 글로벌 평균 약 35% 안팎(2025년 Q2 Adjust 자료 기준)에 그치자, 사용자 단위 추적을 전제로 하던 모바일 어트리뷰션 모델은 사실상 무너졌습니다. 매체사·MMP 누구도 사용자 단위 클릭→설치 매칭을 보장할 수 없게 된 자리입니다. 이 빈자리를 메우기 위해 애플이 직접 OS 차원에서 운영하는 익명 어트리뷰션 프레임워크가 SKAdNetwork(SKAN)이고, 그 후속이 AdAttributionKit(AAK)입니다. 사용자 단위 추적 권한은 사용자에게 돌려주되, 광고 효과는 익명·집계 형태로 측정 가능하게 한 절충점입니다.
1) IDFA 모델 vs SKAN 모델: 무엇이 바뀌었나
ATT 이전 모바일 어트리뷰션은 IDFA(Identifier for Advertisers)라는 디바이스 단위 영구 식별자가 모든 매칭의 축이었습니다. 매체사·SDK·MMP가 이 IDFA를 주고받아 “이 사용자가 어느 광고를 보고 어느 앱을 설치했나”를 사용자 단위로 추적했습니다. ATT 이후로는 사용자가 동의를 거부하면 IDFA가 노출되지 않아, 이 모델 자체가 작동하지 않는 자리가 됐습니다. SKAN은 그 자리를 메우기 위해 어트리뷰션 결정 권한을 매체사에서 OS로 옮긴 새 모델입니다.
두 모델의 차이를 흐름으로 보면 다음과 같습니다.
(1) IDFA 모델 (ATT 동의 사용자, 결정론적 매칭)
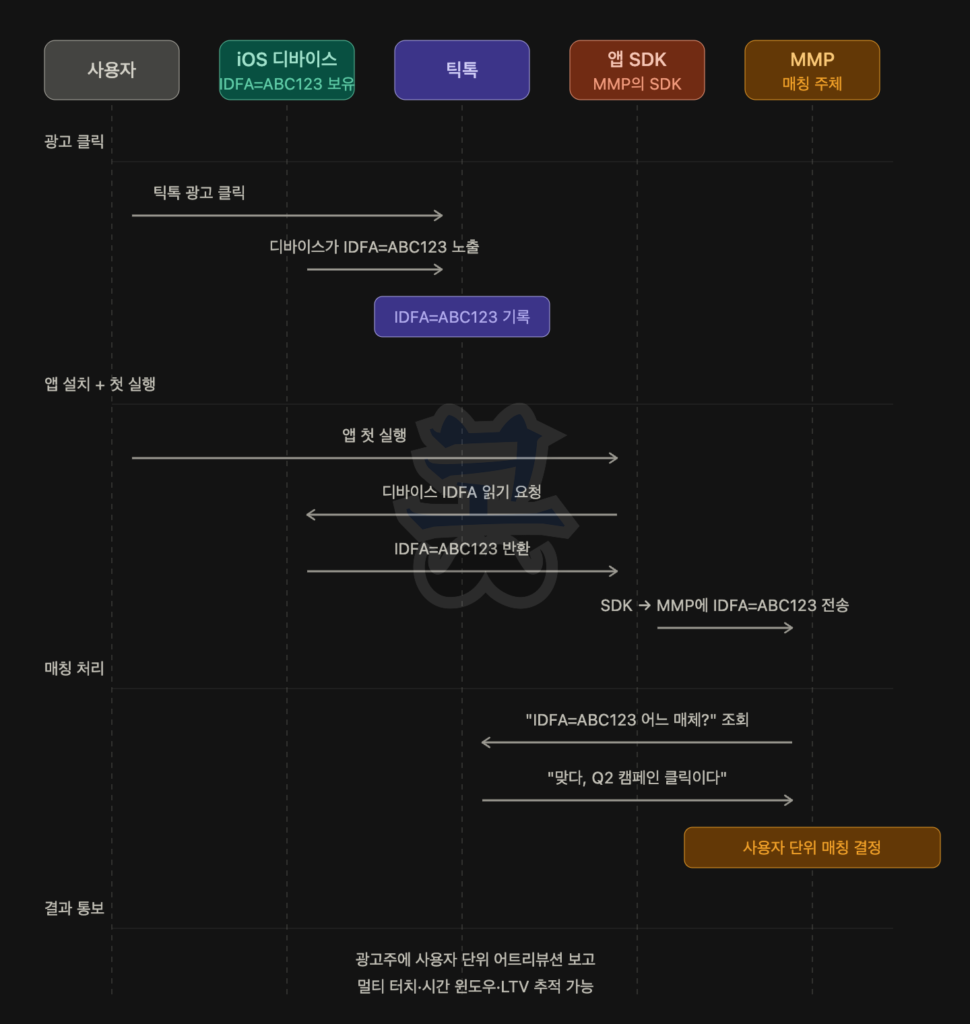
이 모델에서 매체사·SDK·MMP가 모두 사용자 단위로 어트리뷰션 데이터를 주고받습니다. 사용자가 누구인지 추적이 가능하고, 그래서 멀티 터치·시간 윈도우·LTV 추적이 모두 가능합니다.
(2) SKAN 모델 (ATT 거부 사용자, OS 익명 어트리뷰션)
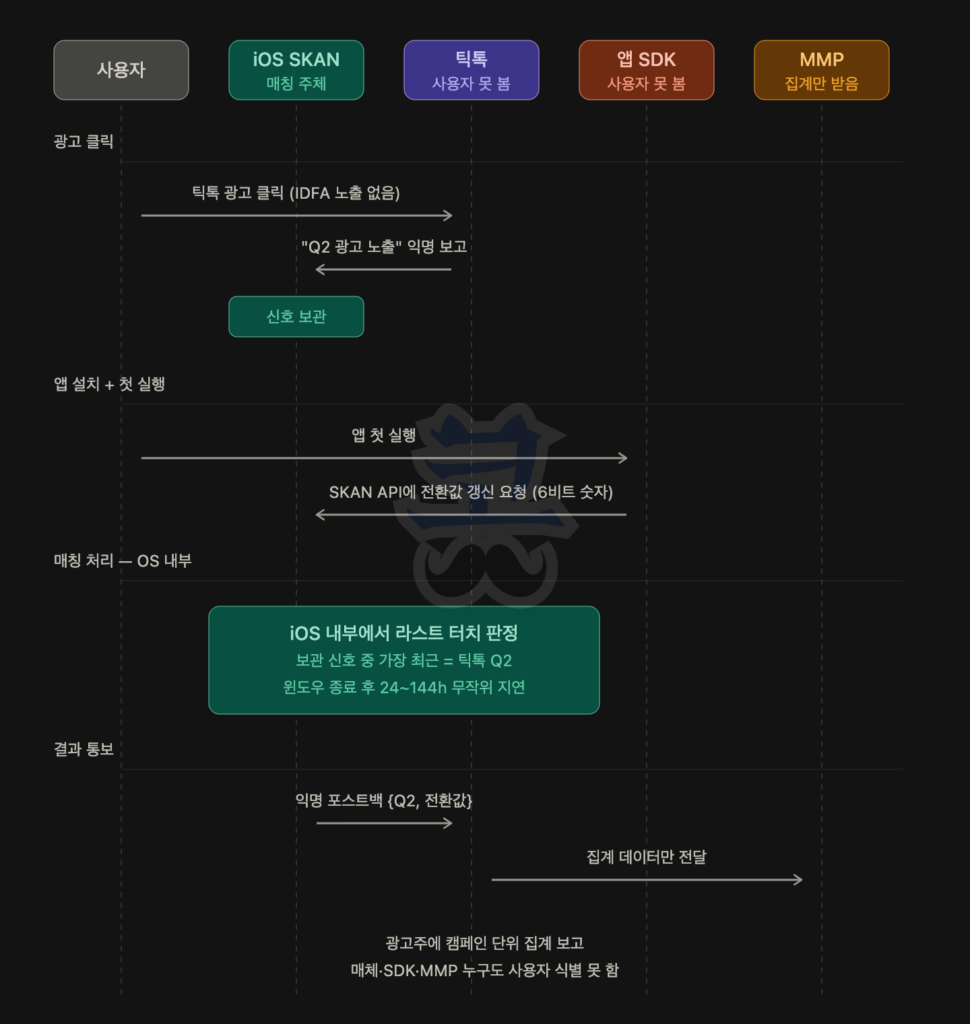
핵심 차이는 어트리뷰션 작업 자체가 OS 안으로 들어갔다는 것입니다. 매체사·SDK가 사용자 단위로 어트리뷰션을 매기던 일을 OS가 가로채서 자기 안에서 익명으로 처리하고, 결과만 집계 형태로 매체사에게 흘려보냅니다.
| 항목 | IDFA 모델 | SKAN 모델 |
|---|---|---|
| 사용자 식별자 | IDFA (영구) | 없음 |
| 어트리뷰션 결정 주체 | 매체사·MMP | OS (애플) |
| 데이터 흐름 시점 | 실시간 | 24~144시간 무작위 지연 |
| 데이터 단위 | 사용자 단위 | 익명 집계 |
| 사용자 단위 LTV 추적 | 가능 | 불가능 (집계 추정만) |
| 멀티 터치 어트리뷰션 | 가능 | 불가능 (OS가 라스트 터치 강제) |
이 모델 전환이 모바일 광고주 운영의 거의 모든 자리를 흔들었습니다. 사용자 단위 LTV 측정이 사라지면서 LTV 기반 입찰 최적화가 어려워지고, 멀티 터치가 막히면서 도입·고려 단계 광고의 기여도를 측정할 수 없게 되고, 24~144시간 지연으로 캠페인 운영의 의사결정 속도가 느려졌습니다. 이 자리들이 SKAN 환경에서 MMP가 새로 정의된 역할(뒤에서 다룸)을 갖게 된 배경입니다.
2) SKAN의 작동 원리 예시
SKAN은 어트리뷰션 결정 권한을 매체사에서 OS로 옮긴 구조입니다. 매체사는 누가 자기 광고를 클릭했는지 알 수 없고, OS가 보내주는 익명 결과(포스트백)를 받아 광고주에게 전달할 뿐입니다.
흐름을 한 시나리오로 따라가 보겠습니다. 캐주얼 게임 앱 “퍼즐X” 광고주가 틱톡에 신규 사용자 획득 캠페인(Q2_신규획득)을 운영하는 자리이고, 전환값 매핑은 다음과 같습니다.
- 0=설치만, 1~10=가입, 11~30=첫 결제, 31~50=누적 결제 5만 원 이상, 51~63=고가 LTV
먼저 광고주는 자기 앱 SDK에 위 매핑을 미리 박아둡니다. 사용자가 앱 안에서 가입·결제 같은 이벤트를 일으키면 SDK가 그 사용자의 전환값을 갱신하고, 측정 윈도우 종료 시점의 마지막 값 한 개가 그 설치의 전환값으로 확정돼 OS가 매체사에게 포스트백으로 보냅니다.
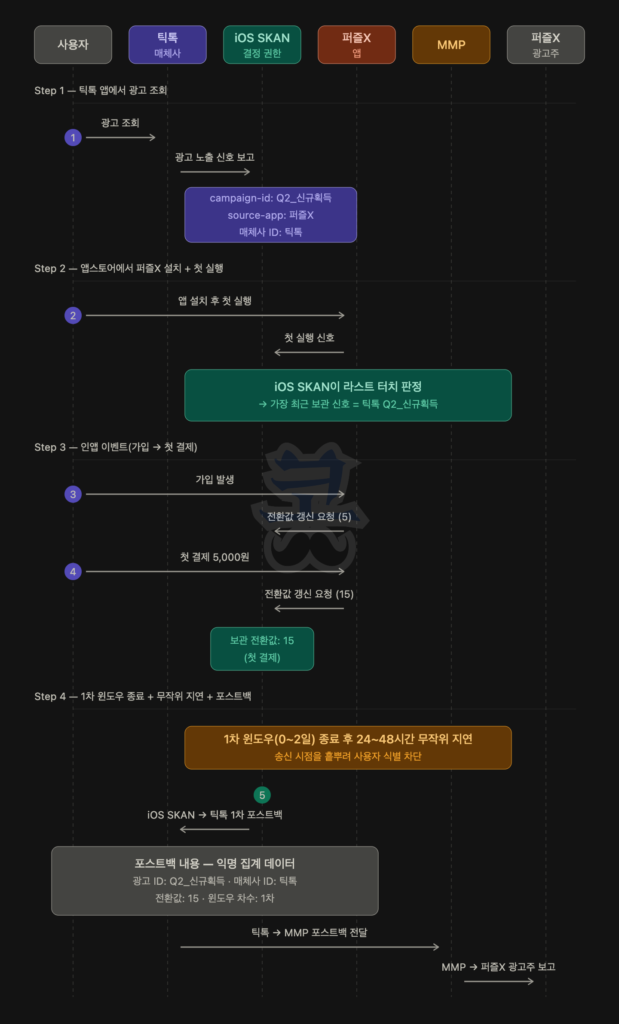
핵심은 OS가 라스트 터치 알고리즘으로 어느 매체사에게 어트리뷰션을 매길지를 직접 결정하고, 무작위 지연 후 익명 결과만 보낸다는 점입니다. 위 시나리오에서 사용자가 가입과 첫 결제까지 두 번의 전환값 갱신을 했지만, 1차 포스트백이 보내는 건 윈도우 종료 시점의 마지막 전환값(15) 한 값뿐입니다. 광고주는 “Q2_신규획득 캠페인에서 설치 1건이 일어났고, 그 사용자가 첫 결제까지 도달했다”는 정보를 얻습니다. 사용자가 누구였는지, 정확히 언제 결제했는지는 알 수 없습니다.
여기서 헷갈릴 자리를 한 번 짚어둡니다. 광고주 앱 SDK가 가입·결제 같은 인앱 이벤트를 관찰하는데 “사용자 추적이 불가능하다”고 하면 모순처럼 들립니다. 두 가지를 구분해야 합니다. 광고주는 자기 앱 안에서 사용자가 누구인지·무엇을 했는지 자기 데이터베이스에 기록할 수 있습니다. 이건 SKAN과 무관합니다. SKAN이 막는 건 그 사용자 정보를 광고 어트리뷰션과 짝짓는 작업입니다. 앱 SDK가 SKAN API에 보내는 건 사용자 ID가 아니라 6비트 전환값 한 개뿐이고, 매체사가 받는 포스트백에도 사용자 ID는 없습니다. 광고주가 받는 보고서는 익명 집계라, 자기 데이터베이스의 특정 사용자를 특정 광고 어트리뷰션과 매핑할 길이 OS 단계에서 끊겨 있습니다.
같은 캠페인의 install 1,000건이 쌓이면 광고주의 성과 보고서는 다음과 같이 집계됩니다. 위 시퀀스의 사용자(전환값 15)는 아래 표에서 “첫 결제(11~30)” 구간에 속한 250명 중 한 명입니다.
Q2_신규획득 캠페인 (틱톡), 1차 포스트백 1,000건 집계
| 전환값 구간 (의미) | 설치 수 | 비율 |
|---|---|---|
| 0 (설치만) | 400 | 40% |
| 1~10 (가입·튜토리얼 통과) | 300 | 30% |
| 11~30 (첫 결제) | 250 | 25% |
| 31~50 (누적 결제 5만 원 이상) | 40 | 4% |
| 51~63 (고가 LTV) | 10 | 1% |
| 합계 | 1,000 | 100% |
광고주는 이 분포로 캠페인의 퍼널 효율(설치 → 가입 → 결제로의 전환율)을 파악하고, 매체별·캠페인별 비교로 예산 배분을 결정합니다. 예를 들어 같은 install 1,000건이라도 메타 캠페인은 “설치” 구간이 60%인데 틱톡은 40%라면, 사용자 품질이 틱톡 쪽이 더 높다는 신호로 읽고 틱톡 예산 비중을 높이는 식입니다. 사용자 단위 LTV 추적은 못 해도, 집계 단위 효율 비교는 가능한 자리입니다.
3) 전환값(Conversion Value): 6비트에 압축한 광고 효과
포스트백 안에 담기는 핵심 데이터가 전환값입니다. 광고주가 비즈니스 의미를 6비트(0~63 범위) 숫자 한 개에 압축해 보내는 신호로, 64개 정수 각각에 다른 의미를 부여할 수 있습니다. 광고주가 직접 매핑 테이블을 설계해 SDK에 박아둡니다.
(1) 매핑 설계 방식 세 가지
광고주 비즈니스 특성에 따라 세 가지 방식 중 하나를 선택합니다.
| 매핑 방식 | 작동 원리 | 적합 자리 |
|---|---|---|
| 상태 매핑(state) | 각 정수가 사용자가 도달한 단계 하나에 1:1 대응 | 게임, 콘텐츠 앱 (도달 단계가 명확) |
| 비트 플래그(bit flag) | 6비트를 6개 이벤트의 on/off 플래그로 사용 | 여러 이벤트 동시 추적 |
| 결합 매핑(combined) | 6비트를 잘게 나눠 여러 차원 동시 측정 (예: 3비트 매출 + 3비트 참여) | 매출과 참여 둘 다 |
(2) 게임 앱의 상태 매핑 예시
| 전환값 | 의미 | 비고 |
|---|---|---|
| 0 | 설치만 | 설치 직후 디폴트 |
| 1 | 첫 실행 | 앱 첫 진입 |
| 2 | 가입 완료 | 회원가입 |
| 3 | 튜토리얼 절반 통과 | 온보딩 중간 |
| 4 | 튜토리얼 완료 | 온보딩 완료 |
| 5 | 첫 레벨 클리어 | 첫 게임 완료 |
| 6 | 친구 초대 | 바이럴 신호 |
| 7~10 | 광고주 추가 정의 영역 | 예: 7일 잔존, 푸시 동의 |
| 11~30 | 첫 결제 (정수마다 가격 구간) | 11 = 첫 결제 1,000원, 12 = 첫 결제 3,000원, …, 30 = 첫 결제 10만 원+ |
| 31~50 | 누적 결제 (정수마다 누적 금액 구간) | 31 = 누적 5만 원~, …, 50 = 누적 100만 원~ |
| 51~63 | 고가 LTV 사용자 (정수마다 LTV 등급) | 63 = 고래 사용자 (누적 500만 원+) |
64개 정수 각각이 서로 다른 사용자 단계를 가리킵니다. 광고주가 자기 비즈니스에 맞춰 세분화 정도를 결정합니다.
표에서 보듯 1, 2, 3 같은 인접 정수도 각각 다른 사용자 단계를 가리킵니다. “1~10이 같은 의미”가 아니라, 광고주가 64개 정수 안에서 자기 비즈니스의 핵심 퍼널을 어떻게 압축해 배치할지 직접 설계해야 합니다. 이 설계가 캠페인 평가의 정밀도를 좌우합니다.
(3) MMP 도구가 자동 생성
기술적으로는 64개 정수의 의미를 모두 광고주가 정의해야 하지만, 실무에서는 손으로 매핑을 짜지 않습니다. MMP가 제공하는 전환값 관리 도구가 광고주 입력을 받아 64개 정수 매핑을 자동 생성합니다.
| MMP / 출처 | 도구 | 작동 방식 |
|---|---|---|
| 앱스플라이어 | Conversion Value Manager | GUI에서 이벤트와 값 구간 선택 → 64개 정수 매핑 자동 생성 |
| 애드저스트 | Conversion Hub | 같은 방식 + 모델별 템플릿 제공 (매출 모델, 참여 모델 등) |
| 싱귤러 | SKAN Manager | 매출·참여·잔존을 결합한 매핑 자동 설계 |
| 애플 자체 | 단순 모드(coarse-grained) | 3단계만 정의 (낮음·중간·높음) |
광고주가 거치는 단계는 다음과 같습니다.
[1] MMP 도구에서 매핑 모델 선택
예: "매출 + 참여 결합 모델"
│
▼
[2] 추적할 이벤트 입력
가입, 첫 결제, 누적 결제, 잔존 등
│
▼
[3] 각 이벤트의 값 구간 정의
예: 첫 결제 1,000원 / 3,000원 / 5,000원 / 10,000원+ …
│
▼
[4] MMP 도구가 64개 정수 매핑 자동 생성
│
▼
[5] 매핑이 앱 SDK에 자동 박힘
이후 사용자 행동에 따라 SDK가 정수 갱신
광고주는 비즈니스 KPI만 정의하면 되고, “정수 12 = 첫 결제 3,000원” 같은 정수 단위 매핑은 도구가 처리합니다. IDFA 시대의 MMP는 사용자 단위 클릭→설치 매칭이 본업이었지만, SKAN 시대의 MMP는 “광고주의 KPI를 6비트에 어떻게 압축할지 컨설팅하고 매핑을 자동 생성하는 도구를 운영하는 것”이 본업이 됐습니다. 뒤에서 다룰 MMP 역할 변화의 구체적 모습이 이 자리입니다.
(4) 6비트 제약이 측정 정밀도에 미치는 영향
| 자리 | IDFA 모델에서 가능했던 것 | SKAN에서 잃은 것 | 광고주 대응 |
|---|---|---|---|
| 결제 금액 | 사용자별 정확한 결제 금액 추적 | 정수 한 개의 가격 구간만 (예: 1,000~5,000원 한 묶음) | 각 정수의 평균값을 가정해 ROAS 추정 |
| 사용자 단위 LTV | 한 사용자의 30일·90일 LTV 정확 측정 | 누구의 LTV인지 알 수 없음 | 1차·2차·3차 포스트백 분포로 평균 LTV 추정 (예측 LTV(predictive LTV) 모델) |
| 코호트 분석 | 가입 코호트별 잔존·매출 곡선 | 코호트 멤버 식별 불가 | 캠페인 단위 집계 곡선만 비교 |
광고주는 사용자 한 명 한 명의 정확한 LTV는 못 잡고, 캠페인 간 상대 비교(메타 캠페인 평균 LTV vs 틱톡 캠페인 평균 LTV)에 만족해야 하는 자리에 들어왔습니다.
(5) 세밀 모드 vs 단순 모드
SKAN 4부터 두 가지 모드를 선택할 수 있게 됐습니다.
| 모드 | 영문 | 사용 단계 | 적합 자리 |
|---|---|---|---|
| 세밀 모드 | fine-grained | 64단계 (0~63 전체 사용) | 트래픽 큰 캠페인 (월 install 수천 건+) |
| 단순 모드 | coarse-grained | 3단계 (낮음·중간·높음, low·medium·high) | 트래픽 작은 캠페인 (임계값 통과 우선) |
두 모드의 차이는 다음에 설명할 프라이버시 임계값과 직결됩니다.
같은 설치 100건일 때
[세밀 모드 64단계]
한 단계당 평균: 100 / 64 ≈ 1.5명
→ 임계값(통상 캠페인·앱·일 기준 약 20건) 못 통과 → OS가 데이터 가림
[단순 모드 3단계]
한 단계당 평균: 100 / 3 ≈ 33명
→ 임계값 통과 → 최소한의 결과 받음
광고주는 캠페인 트래픽 규모에 따라 두 모드를 골라 쓰는데, 큰 캠페인은 세밀 모드로 디테일을 우선하고, 작은 캠페인은 단순 모드로 데이터 가용성을 우선합니다.
4) 익명화: 무작위 지연 + 프라이버시 임계값
발송 지연에 무작위 노이즈가 들어가는 이유는 시간 기반 재식별을 막기 위함입니다. 매체사가 “오후 3시에 광고 클릭한 사용자가 ABC였다”는 정보를 갖고 있을 때, 포스트백이 그 직후 정해진 시점에 도착하면 매체사는 두 시점을 매칭해 ABC가 전환했음을 역추적할 수 있습니다. 24~144시간 사이 무작위 지연을 두면 이 시간 매핑이 끊어져 개별 사용자 재식별이 통계적으로 불가능해집니다.
추가로 프라이버시 임계값(crowd anonymity threshold)이 있습니다. 같은 캠페인의 install 수가 일정 기준 미만이면 OS가 매체사 ID를 익명 처리하거나 전환값 자체를 보내지 않습니다. 적은 사용자 풀에서는 한 사람만 식별돼도 재식별 위험이 커지기 때문입니다. 그래서 SKAN은 트래픽 큰 캠페인에서는 풍부한 데이터를 주지만, 트래픽 적은 캠페인은 거의 빈 결과만 받게 됩니다. 광고주가 작은 캠페인에서 결과가 비어 보고된다고 매체사를 의심할 게 아니라, 임계값에 못 미친 결과일 가능성을 먼저 봐야 하는 자리입니다.
5) SKAN 3에서 SKAN 4로: 단일 포스트백에서 3단계로
SKAN 3까지는 포스트백이 설치 직후 한 번뿐이었습니다. 광고주는 install 시점의 전환값만 받고, 7일째 결제나 30일째 잔존 같은 이후 사용자 행동은 측정할 수 없었습니다. 모바일 게임 광고주가 LTV 추정에 가장 답답해하던 자리입니다. SKAN 4(2022년 발표)부터 포스트백이 3단계 윈도우로 나뉘면서, 단기·중기·장기 효과를 따로 측정할 수 있게 됐습니다.
| 포스트백 | 측정 윈도우 | 발송 지연 | 측정 대상 | 활용 예 |
|---|---|---|---|---|
| 1차 | 0~2일 | 24~48시간 무작위 | 초기 온보딩 신호 | 가입 완료, 튜토리얼 통과 |
| 2차 | 3~7일 | 24~144시간 무작위 | 참여 깊이 | 활성 사용자, 첫 결제 |
| 3차 | 8~35일 | 24~144시간 무작위 | 잔존·매출 | 잔존율, LTV 추정 |
3단계 분할로 광고주는 설치 직후 효과뿐 아니라 한 달짜리 잔존·LTV까지 측정할 수 있게 됐습니다. 다만 각 포스트백에 담을 수 있는 정보는 여전히 6비트 범위에 묶여 있어, 한 단계의 풍부한 디테일을 모두 담지는 못합니다.
6) AAK: SKAN의 후속 프레임워크
AAK(AdAttributionKit)는 2024년 6월 애플 세계 개발자 회의(WWDC, Worldwide Developers Conference)에서 SKAN의 후속으로 공개된 어트리뷰션 프레임워크입니다. iOS 17.4(2024년 3월)부터 도입됐고, SKAN의 핵심 설계(OS 단계 익명 어트리뷰션, 포스트백, 전환값)는 그대로 가져가되 SKAN이 구조적으로 못 다루던 자리들을 새로 채워 넣었습니다.
(1) AAK가 SKAN과 가장 다른 자리: 재참여 측정
SKAN의 가장 큰 한계는 신규 install만 어트리뷰션할 수 있다는 점이었습니다. 이미 앱을 설치한 사용자에게 광고를 보여 다시 활성화시키는 리타게팅·재참여 캠페인의 효과를 측정할 길이 없었습니다. 모바일 게임·구독 앱처럼 잔존 사용자 재활성화가 매출의 절반을 만드는 비즈니스에게 SKAN은 핵심 캠페인 절반을 측정 못 하는 도구였습니다.
AAK는 재참여 어트리뷰션(re-engagement attribution)을 새로 열었습니다. 광고주는 신규 사용자 획득과 기존 사용자 재참여를 같은 프레임워크 안에서 측정하고 비교할 수 있게 됐고, 잔존·재활성 캠페인의 ROAS 평가가 처음으로 가능해졌습니다.
(2) WWDC 2025에서 공유된 5가지 추가 업그레이드 (iOS 18.4부터 순차 도입)
| 업그레이드 | 영문 | 해결한 자리 |
|---|---|---|
| 중첩 재참여 전환 윈도우 | Overlapping re-engagement windows | 여러 재참여 캠페인을 동시에 운영할 때 윈도우가 충돌해 측정이 누락되던 자리 |
| 광고주 설정 어트리뷰션·연속 전환 차단 윈도우 | Configurable attribution & cooldown intervals | 윈도우 길이가 OS에 의해 고정돼 캠페인 특성(짧은 이벤트성 vs 장기 잔존)에 맞출 수 없던 자리 |
| 포스트백 국가 코드 포함 | Country codes in postbacks | 포스트백에 지역 정보가 없어 국가별 캠페인 효율 비교가 불가능했던 자리 |
| 멀티 스토어 측정 | Multi-store coverage | App Store 외 EU의 외부 마켓플레이스·사이드로딩 측정이 안 되던 자리 (DMA 대응) |
| 개발자 테스트 도구 | Developer testing tool | 라이브 캠페인에서만 어트리뷰션 셋업을 검증할 수 있어, 잘못 설정된 매핑이 운영 중에야 발견되던 자리 |
(3) 왜 SKAN과 AAK가 공존하는가
AAK가 SKAN의 후속이지만 SKAN을 교체하지 않고 공존하는 데는 두 가지 이유가 있습니다.
| 자리 | 내용 |
|---|---|
| 호환성 | SKAN은 iOS 14부터 작동하지만 AAK는 iOS 17.4 이상에서만 작동. iOS 16 이하 사용자가 여전히 남아 있어 광고주는 두 프레임워크를 모두 운영해야 함 |
| 생태계 도입 | AAK가 작동하려면 매체사·MMP·광고주 앱 SDK가 모두 AAK를 지원해야 함. 셋 중 하나라도 정렬되지 않으면 AAK는 작동 불가. 2026년 현재까지도 시장 무게중심은 SKAN 쪽 |
광고주 운영 관점에서는 자기 캠페인의 사용자 풀(iOS 17.4 이상 비중)과 매체사·MMP의 AAK 지원 범위를 보고 SKAN 단독, AAK 단독, 또는 둘 다 병행 중에서 선택합니다. 신규 측정·재참여·EU 외부 스토어 측정이 필요한 광고주는 AAK 비중을 높이고, 호환성을 우선하는 광고주는 SKAN 단독 운영을 유지합니다. 2026년 5월 현재 SKAN과 AAK는 공존 상태이고, AAK 비중이 매년 늘어나는 흐름입니다.
7) SKAN/AAK 환경에서 MMP의 역할 분기
이 환경에서 MMP의 역할이 iOS와 Android에서 완전히 다르게 정의됐습니다.
| OS | 측정 모델 | MMP의 핵심 업무 |
|---|---|---|
| iOS (ATT 거부 사용자) | SKAN·AAK 집계 포스트백 | 포스트백 해석, 전환값 매핑, 예측 LTV 모델링 |
| Android | GAID 기반 결정론적 SDK 측정 | 사용자 단위 클릭→설치→인앱 이벤트 연결 (기존 모델 유지) |
iOS에서 MMP는 더 이상 사용자 단위 추적자가 아닙니다. 광고주가 정의한 비즈니스 KPI를 6비트 전환값에 어떻게 매핑할지 컨설팅하고, 매체사가 받은 익명 포스트백을 해석해 광고주가 이해할 수 있는 보고서로 가공하는 역할로 옮겨갔습니다. 설치 이후 LTV는 직접 측정이 불가능하니, 적은 신호로 LTV를 추정하는 예측 모델(predictive LTV) 운영이 핵심 차별점이 됐습니다.
Android에서 MMP의 역할은 기존 그대로입니다. GAID 기반 결정론적 매칭으로 사용자 단위 클릭→설치→인앱 이벤트를 100% 연결합니다. 같은 MMP가 한 플랫폼 안에서 두 개의 완전히 다른 측정 모델을 동시에 운영하는 셈이고, 이 이중 환경을 광고주에게 일관된 보고서로 정리해 주는 능력이 MMP 사업자 간 차별점이 됐습니다.
6. 고급 측정: 증분 효과, 브랜드 리프트, 미디어 믹스 모델링(MMM)
어트리뷰션·픽셀·서버사이드를 다 갖춰도 풀리지 않는 질문이 있습니다.
광고를 안 했으면 어떻게 됐을까?
이 질문에 답하는 것이 고급 측정의 영역입니다. 그리고 이 영역은 쿠키 종말 흐름과 맞물려 2024~2026년 사이에 가장 빠르게 발전한 자리입니다.
1) 증분 효과: 진짜 광고 효과
증분 효과 측정은 광고를 본 사람과 안 본 사람의 행동 차이를 비교합니다. 처치군(treatment)과 통제군(control)을 나누고, 두 그룹의 전환율 차이가 광고가 가져온 진짜 추가 효과입니다. 어트리뷰션이 “공이 누구 거냐”에 답한다면, 증분 효과는 “공이 진짜로 있었냐”에 답합니다.
실용적인 구현 방식은 4가지로 갈립니다.
| 방법 | 작동 방식 | 강점 | 비용 |
|---|---|---|---|
| 지오 홀드아웃(Geo Holdout) | 한 지역은 노출, 다른 지역은 미노출 | 커넥티드 TV(CTV, Connected TV)·옥외 광고(OOH, Out-of-Home) 같이 사용자 단위 측정이 어려운 광고에 유효 | 미노출 지역의 매출 손실 |
| 고스트 애드(Ghost Ads) | 입찰만 하고 통제군에 광고 안 보임 | 같은 자리·같은 사용자 비교라 가장 정밀 | 광고 플랫폼이 지원해야 함 |
| 공익 광고 테스트(PSA test) | 통제군에 공익 광고 보임 | “광고 자체의 자극” 통제 | 공익 광고 노출 비용 |
| 컨버전 리프트(Conversion Lift) | 메타·구글이 자체 도구로 자동 분할 | 별도 인프라 없이 시작 가능 | 매체가 제공해야 사용 가능 |
지오 홀드아웃이 가장 직관적이지만 지역별 다른 변수(계절성, 경쟁 광고)를 통제하기 어렵습니다. 고스트 애드는 같은 슬롯의 같은 사용자 풀에서 노출 여부만 가르기 때문에 학술적으로 가장 깨끗하지만 매체사가 지원해야 합니다. 공익 광고 테스트는 통제군도 광고를 받아 “광고를 받았다는 것 자체의 영향”이 통제되는 대신 공익 광고 노출 비용이 추가됩니다. 컨버전 리프트는 광고주가 별도 인프라 없이 시작할 수 있어 가장 가벼운 옵션입니다.
2) 브랜드 리프트: 인지·선호도의 변화
인지도 캠페인은 ROAS로 평가하기 어렵습니다. 인지·선호도·구매 의향이 광고 직후 매출로 바로 환산되지 않기 때문입니다. 이걸 설문으로 측정하는 게 브랜드 리프트 스터디(Brand Lift Study)입니다.
[광고 노출 가능 사용자]
│
무작위 분할
┌─────┴─────┐
▼ ▼
[노출 그룹] [통제군]
│ │
└─── 캠페인 종료 후 ───┐
▼
두 그룹 모두에 같은 1문항 설문
("이 브랜드를 들어보셨나요?")
│
▼
두 그룹 답변 차이 = 브랜드 리프트
캠페인 시작 전에 브랜드 리프트 스터디를 설정해야 통제군이 정상적으로 잡히고, 보통 2~4주의 캠페인 윈도우로 진행됩니다. 구글은 브랜드 리프트 외에 광고 노출 후 브랜드 검색량 증가를 측정하는 서치 리프트(Search Lift), 전환 증가를 측정하는 컨버전 리프트도 같은 실험 설계 위에서 자체 도구로 제공합니다. 메타도 컨버전 리프트와 브랜드 리프트를 자체 제공합니다.
3) MMM: 채널 단위 통계 회귀
미디어 믹스 모델링(MMM, Media Mix Modeling)은 광고 채널별 매출 기여도를 통계 모델로 분해해 추정하는 도구입니다. 사용자 단위가 아니라 채널 단위·기간 단위 데이터를 쓰기 때문에 쿠키 차단·iOS ATT의 영향을 거의 받지 않습니다. 이게 MMM이 다시 주목받는 결정적 이유입니다.
MMM의 뿌리는 1949년 Borden이 제시한 마케팅 믹스(marketing mix) 개념(이후 1960년 McCarthy가 4P로 정리)으로 거슬러 올라갑니다. 통계 모델로서의 MMM은 1970년대 시카고대 통계학자들이 처음 개발했고, 1990년대 빅데이터 시대에 대기업 위주로 자리 잡았다가, 2020년대 들어 쿠키리스 흐름을 타고 부활기를 맞았습니다. 사용자 단위 어트리뷰션이 약해진 자리에 채널 단위 측정 도구가 다시 필요해진 게 부활의 동력입니다.
(1) MMM이 답하는 질문 vs 어트리뷰션이 답하는 질문
| 질문 | 어트리뷰션 | MMM |
|---|---|---|
| “이 사용자가 어느 광고로 들어왔나” | 가능 | 불가능 |
| “전체 매출 중 TV 광고가 기여한 비율” | 불가능 | 가능 |
| “구글 광고비를 30% 늘리면 매출이 얼마나 늘까” | 불가능 | 가능 (예측) |
| “광고 안 했으면 매출이 얼마였을까 (베이스라인)” | 불가능 | 가능 |
| “오늘 일어난 전환을 어느 캠페인에 매길까” | 가능 | 불가능 |
MMM은 사용자 단위 추적이 아니라 매출 분해를 하는 도구라, 어트리뷰션이 못 푸는 질문을 풉니다. 분해 결과는 다음 같은 형태로 나옵니다.
한 분기 매출 100억 원 분해
│
├── 베이스라인 (광고 없이 자연 발생) : 60억 (60%)
│
├── TV 광고 기여 : 12억 (12%)
├── 디지털 디스플레이 기여 : 8억 (8%)
├── 검색 광고 기여 : 10억 (10%)
├── SNS 광고 기여 : 6억 (6%)
├── 옥외광고 기여 : 2억 (2%)
│
└── 통제 변수 (계절성·프로모션 등) : 2억 (2%)
광고주는 이 분해 결과로 채널별 한계 ROAS를 비교하고, 다음 분기 예산을 어디에 더 넣고 어디서 뺄지 결정합니다.
(2) 필요한 데이터
| 데이터 | 단위 | 최소 기간 |
|---|---|---|
| 채널별 광고비 | 일·주 단위 | 2~3년 |
| 매출 또는 전환 수 | 일·주 단위 | 2~3년 |
| 통제 변수 (계절성, 프로모션, 경쟁사 활동, 기상·휴일·경기) | 일·주 단위 | 2~3년 |
통제 변수가 빠지면 모델이 “블랙 프라이데이 매출 폭증”을 광고 효과로 잘못 매기는 오류가 납니다. 데이터 요건이 까다로워 신규 광고주·신생 채널에는 적용이 어렵고, 보통 2~3년치 시계열을 가진 중대형 광고주가 운영합니다.
(3) MMM이 단순 회귀와 다른 두 가지 핵심 기술 1: 애드스톡(Adstock)
이상적으로는 매출(t) = β₀ + β₁ × TV광고비(t) + β₂ × 디지털광고비(t) + ... 같은 단순 선형 회귀로 풀고 싶지만, 광고 효과는 두 가지 비선형성을 가집니다. MMM은 이 두 비선형성을 모델 안에 명시적으로 넣습니다.
오늘 본 광고가 오늘 매출만 만드는 게 아니라 며칠~몇 주에 걸쳐 효과가 잔존합니다. 애드스톡은 이 잔존을 감쇠율(λ)로 모델링합니다.
[감쇠율 λ = 0.5인 경우]
오늘 노출 ── 100% ──→ 오늘 매출 효과
└── 50% ───→ 내일 매출 효과
└── 25% ───→ 모레 매출 효과
└── 12.5% ─→ 그다음 날 매출 효과
...
채널별로 잔존 길이가 다른 게 핵심입니다.
| 채널 | 감쇠율(λ) 통상 범위 | 잔존 패턴 |
|---|---|---|
| TV·옥외광고 | 0.6~0.8 | 인지 형성에 시간 걸려 오래 잔존 |
| 디지털 디스플레이 | 0.3~0.5 | 중간 |
| 검색 광고 | 0.1~0.3 | 사용자가 의도를 갖고 검색해 즉시 반응, 잔존 짧음 |
채널별 감쇠율을 따로 추정하지 않고 모든 채널에 같은 값을 쓰면 MMM이 채널 효과를 잘못 매깁니다. 이게 MMM 추정에서 가장 많은 계산이 들어가는 자리입니다.
(4) MMM이 단순 회귀와 다른 두 가지 핵심 기술 2: 포화 곡선(Saturation Curve)
광고비를 두 배로 쓰면 매출이 두 배가 되는 게 아닙니다. 초기에는 빠르게 매출이 늘다가 일정 지점을 넘으면 추가 광고비가 거의 매출을 만들지 못하는 포화 자리에 들어갑니다. 힐 함수(Hill function)로 모델링하는 게 표준입니다.
매출 ▲
│ ────────── ← 포화: 1원 더 써도 효과 거의 없음
│ ╱
│ ╱ ← 한계 ROAS가 빠르게 떨어지는 자리
│ ╱
│ ╱ ← 효율적 구간
│ ╱
│ ╱ ← 초기 가파른 증가
└────────────────→ 광고비
힐 함수: f(x) = x^α / (K^α + x^α)
K = 절반 포화점 (이 광고비에서 최대 효과의 50% 달성)
α = 곡선 기울기
포화 곡선이 있어야 MMM은 “다음 1원을 어느 채널에 쓰는 게 효율적인가(한계 ROAS, marginal ROAS)”라는 질문에 답할 수 있습니다. 검색 광고가 이미 포화 구간에 있으면 디스플레이로 옮기는 게 한계 ROAS가 더 높다는 식의 결정이 여기서 나옵니다.
(5) MMM의 한계
| 한계 | 의미 |
|---|---|
| 데이터 요건 | 2~3년치 시계열 데이터 필요. 신규 광고주·신생 채널은 적용 불가 |
| 다중공선성 | 여러 채널이 함께 움직이면(같은 시기 동시 인상) 채널별 기여도 분리가 어려움 |
| 단기 의사결정 부적합 | 분기·연 단위 의사결정용. 일·주 단위 캠페인 운영에는 어트리뷰션이 더 맞음 |
| 크리에이티브·오디언스 분해 불가 | 채널 단위까지만 봄. “어느 광고 소재가 효과적이었나”는 측정 불가 |
이 한계 때문에 MMM은 어트리뷰션·증분 효과 측정과 함께 운영하는 삼각 측정의 한 축이지, 단독으로 광고 측정을 끝내는 도구가 아닙니다.
(6) 오픈소스 도구 두 가지: 메타 로빈과 구글 메리디안
이 영역은 2024~2025년 사이 두 오픈소스 도구로 사실상 부활기를 맞았습니다.
| 항목 | 메타 로빈(Meta Robyn) | 구글 메리디안(Google Meridian) |
|---|---|---|
| 출시 | 2020년 오픈소스화 | 2025년 1월 정식 공개 |
| 추정 방식 | 릿지 회귀(Ridge regression) | 베이지안 회귀(Bayesian regression) |
| 최적화 | Nevergrad 진화(evolutionary) 알고리즘 하이퍼파라미터 탐색 | MCMC(Markov Chain Monte Carlo) 샘플링 |
| 결과 형태 | 단일 점 추정 (예: ROAS 3.2) | 확률 분포 (예: ROAS 95% 신뢰구간 2.8~3.6) |
| 보정 방식 | 외부 실험 결과(컨버전 리프트)로 보정 | 사전 지식·실험 결과를 베이지안 prior로 통합 |
| 지역 단위 모델링 | 미지원 | 지원 (지역별 효과 분리) |
| 강점 | 빠른 자동화, R/Python 기반 | 불확실성(uncertainty) 제공, 구글 애즈·유튜브 데이터 통합 |
광고주가 의사결정 자리에서 단일 숫자(ROAS = 3.2)가 아니라 신뢰구간(ROAS 2.8~3.6)을 보면, “확실히 효율이 높다”와 “효율이 높을 수도 있다”를 구분해 더 신중한 예산 배분을 할 수 있다는 게 메리디안의 차별점입니다. 단일 추정치만 보면 운 좋게 추정값이 높게 나온 채널에 과도하게 예산을 몰아 손실로 이어지는 자리가 생기는데, 베이지안 신뢰구간이 그 위험을 시각화합니다.
4) 어트리뷰션·증분 효과·MMM의 분업
이 세 가지는 경쟁이 아니라 분업 관계입니다.
| 도구 | 시간 단위 | 역할 | 쿠키 종말 영향 |
|---|---|---|---|
| 어트리뷰션 | 일·주 | 일상 캠페인 운영 (전술적, tactical) | 큼 |
| 증분 효과 | 단기·중기 | 핵심 가설 검증 | 작음 |
| MMM | 분기·연 | 채널 예산 배분 (전략적, strategic) | 거의 없음 |
2026년 측정 트렌드는 이 세 가지를 함께 쓰는 삼각 측정(triangulation)입니다. MMM 결과와 어트리뷰션 결과가 어긋나는 자리에 증분 효과 실험을 돌려 어느 쪽이 진짜에 가까운지 결정하는 식입니다. 한 가지에만 의존하던 시대가 끝났다는 게 측정 인프라의 큰 흐름입니다.
광고비를 어떤 단위로 매기고 어떤 지표로 평가하느냐가 캠페인의 표준 어휘를 정합니다. 그 위에서 한 사용자의 여러 접점 중 어느 광고에 매출을 매기는가의 결정이 어트리뷰션이고, 이 결정 권한이 환경에 따라 누구에게 있는지가 갈립니다. 데스크톱 웹에서는 광고주의 어트리뷰션 도구(GA4 등)가, 모바일에서는 MMP가, iOS의 식별자 단절 자리에서는 OS(애플)가 권한을 가져갔습니다.
다만 어트리뷰션은 한 가지 전제 위에서 작동합니다. “광고를 본 사용자가 누구인지 추적할 수 있다”는 전제입니다. 데스크톱 웹에서는 쿠키가, 모바일에서는 디바이스 식별자가 그 추적의 축이었습니다. 이 축이 쿠키 차단과 ATT로 흔들린 뒤, 웹은 어떤 답을 만들었는가. 다음 편(7-2)이 그 자리입니다. 클라이언트 사이드 픽셀과 GA4가 어떻게 변했는지, 잃은 신호를 회수하기 위해 서버사이드 인프라(서버사이드 GTM, CAPI, 향상된 전환)가 어떻게 등장했는지, 그리고 EMQ 점수와 event_id 중복 제거 같은 새 운영 어휘가 왜 광고주의 일상 업무가 됐는지를 봅니다.
프로그래매틱 광고 시리즈
(2) 광고가 거래되는 시장: 오픈 웹, 월드 가든, 리테일 미디어
(4) RTB와 헤더 비딩의 메커니즘: 100ms 안의 경매
(5) 데이터와 식별자: 광고가 “나에게 맞는 광고”가 되는 원리
(6) 크리에이티브와 캠페인 운영: 광고를 만들고 올리기
(7)-① 측정·어트리뷰션·검증: 광고비와 성과 측정의 기본