
앞 편(7-1)에서 어트리뷰션이 한 가지 전제 위에서 작동한다는 자리에서 멈춰섰습니다. “광고를 본 사용자가 누구인지 추적할 수 있다”는 전제입니다. 데스크톱 웹에서는 쿠키가, 모바일에서는 디바이스 식별자가 그 추적의 축이었습니다. 이 축이 쿠키 차단과 ATT로 흔들린 뒤, 광고주는 잃은 신호를 회수하기 위한 새 인프라가 필요해졌습니다.
7-2편은 그 인프라의 두 층을 다룹니다. 첫 번째 층은 신호를 잡는 부분입니다. 광고주 사이트에 심는 픽셀(메타 픽셀, 틱톡 픽셀 등)과 웹 애널리틱스의 표준이 된 GA4가 쿠키 종말 환경에서 어떻게 변했는지를 봅니다. 두 번째 층은 잃은 신호를 회수하는 부분입니다. 사파리의 ITP, 애드블록, 사용자 동의 거부로 30~50% 손실되는 신호를 메우기 위해 등장한 서버사이드 인프라(서버사이드 GTM, 메타의 전환 API(CAPI), 구글의 향상된 전환)가 그 층입니다.
1. 웹 트래킹: 픽셀과 GA4의 세계
모바일에 MMP가 있다면, 웹에는 픽셀과 애널리틱스가 있습니다. 그리고 이쪽도 쿠키 종말로 큰 변화를 겪고 있습니다.
1) GA4와 동작 모델링
웹 애널리틱스의 표준은 구글 애널리틱스 4(Google Analytics 4, GA4)입니다. 2023년 7월 유니버설 애널리틱스(Universal Analytics, UA)가 종료되면서 GA4가 자리를 이어받았고, 페이지뷰가 아닌 이벤트 단위 데이터 모델로 설계됐습니다. 쿠키 종말에 맞춘 새 측정 방식이 동작 모델링(behavioral modeling)입니다.
사용자 진입
│
▼
[동의 여부]
│
├── 동의 ──→ 쿠키 기반 정상 측정
│
└── 거부 ──→ 쿠키리스 핑 (cookieless ping, 최소 신호)
│
▼
머신러닝이 동의한 비슷한 사용자 패턴으로
거부 사용자의 행동을 추정 → 보고에 반영
활성화에는 다음 요건을 모두 충족해야 합니다.
| 요건 | 기준 |
|---|---|
| 동의 사용자(granted) 일 사용자 수 | 1,000명 이상 (최근 28일 중 7일 이상) |
| 동의 거부 사용자(denied) 일 이벤트 수 | 1,000건 이상 (최소 7일 이상) |
| 동의 모드 구현 | 전체 페이지·앱 화면에 적용, 동의 다이얼로그 노출 전 태그가 로드되도록 설정 |
GA4 보고서의 일부 전환 숫자가 실측이 아닌 추정값이라는 점이, 쿠키리스 시대의 측정이 어떤 모습이 됐는지를 보여줍니다.
2) 채널별 픽셀
광고 채널별로는 각자의 픽셀이 따로 있습니다.
| 도구 | 운영 주체 | 역할 |
|---|---|---|
| 메타 픽셀(Meta Pixel) | 메타 | 페이스북(Facebook)·인스타그램(Instagram) 광고 어트리뷰션, 오디언스 빌딩 |
| 틱톡 픽셀(TikTok Pixel) | 틱톡 | 틱톡 광고 측정 |
| 링크드인 인사이트 태그(LinkedIn Insight Tag) | 링크드인 | B2B 광고 측정 |
| 마이크로소프트 UET(Microsoft Universal Event Tracking) | 마이크로소프트(Microsoft) | 빙(Bing) 광고 측정 |
| 구글 애즈 태그(Google Ads Tag) | 구글 | 구글 애즈 측정 (GA4와 별도) |
픽셀의 본질은 광고주 사이트에 심는 자바스크립트 코드입니다.
fbq('track', 'Purchase', {value: 50000, currency: 'KRW'});이 한 줄이 사용자 브라우저에서 메타 서버로 HTTP 요청을 보내고, 메타는 이 데이터를 자기 광고가 가져온 결과로 인식합니다. 단 사파리(Safari)의 지능형 추적 방지(ITP, Intelligent Tracking Prevention)나 파이어폭스(Firefox)의 강화된 추적 방지(ETP, Enhanced Tracking Protection) 환경에서는 이 호출이 퍼스트파티(1st-party, 광고주 도메인 자체의 쿠키) 컨텍스트에서 일어나도록 설정해야 부분적으로라도 데이터를 회수할 수 있습니다.
3) UTM 파라미터와 단편화
UTM(Urchin Tracking Module) 파라미터는 URL에 추가하는 식별 표시입니다. utm_source=newsletter&utm_medium=email&utm_campaign=summer_sale 식으로 붙이면 웹 애널리틱스가 그 트래픽이 어디서 왔는지 자동으로 분류합니다. 전 세계 웹 애널리틱스의 사실상 공통 표준입니다.
문제는 한 광고주 사이트에 픽셀이 5~10개 동시에 작동하는 게 흔하다는 점입니다. 메타·구글·틱톡·링크드인·마이크로소프트가 각자 자기 픽셀을 심으라고 요구합니다. 광고주는 모두 심지만, 사이트 로딩이 느려지고 같은 전환을 여러 채널이 자기 공으로 가져가는 자기 평가 문제가 그대로 남습니다. 이 단편화 문제를 풀기 위해 6번 섹션의 태그 관리 도구가 등장했습니다.
2. 태그 관리와 서버사이드: 측정 인프라의 이동
사이트마다 픽셀이 5~10개씩 심어진 환경에서 이걸 묶어 관리할 도구가 필요해졌습니다. 그게 구글 태그 매니저(Google Tag Manager, GTM)이고, 쿠키 종말로 이 영역이 다시 한 번 서버사이드로 옮겨가고 있습니다.
1) GTM과 서버사이드의 두 갈래
웹 트래킹의 기본은 클라이언트 사이드입니다. 사용자 브라우저에 픽셀(자바스크립트 코드 한 줄)을 심어, 사용자가 페이지를 열거나 전환 액션을 할 때마다 그 신호를 광고 채널로 직접 보내는 방식입니다. 구현이 가장 단순하고 비용이 낮아 모든 광고주의 출발점이지만, 사파리의 ITP·파이어폭스의 ETP, 애드블록(adblock) 확장 프로그램, 사용자의 쿠키 동의 거부에 직접 노출돼 신호가 30~50% 손실되는 환경이 됐습니다.
이 손실을 회복하기 위해 등장한 것이 서버사이드 트래킹입니다. 브라우저에서 광고 채널로 신호를 직접 보내는 대신, 광고주 서버가 신호를 받아 거기서 광고 채널 서버로 보내는 방식입니다. 브라우저 차단을 우회하고 사용자 동의 처리도 광고주 도메인 안에서 일어나, 잃었던 신호를 상당 부분 회복합니다. 서버사이드는 한 가지 인프라가 아니라 두 갈래(sGTM과 직접 CAPI 호출)로 나뉩니다.
GTM(Google Tag Manager)은 클라이언트 사이드와 서버사이드 모두를 관리하는 태그 매니저입니다. 사이트에 컨테이너 코드를 한 번만 심으면 그 안에서 모든 태그를 GUI로 관리할 수 있고, 마케터가 개발자 손을 거치지 않고 태그를 추가·변경할 수 있는 게 장점입니다. GTM은 클라이언트 컨테이너로 시작했지만 서버사이드 컨테이너(sGTM)도 같은 GUI에서 관리할 수 있도록 확장됐고, 그래서 서버사이드의 첫 갈래로 자리 잡았습니다.
클라이언트 사이드 한 가지와 서버사이드 두 갈래까지, 세 가지 접근 방식의 차이는 다음과 같습니다.
| 측정 인프라 | 동작 위치 | 운영 주체 | 도입 비용 | 데이터 손실 회복 |
|---|---|---|---|---|
| 클라이언트 사이드 | 사용자 브라우저·앱 | 마케터 | 낮음 (픽셀만 심기) | 차단·동의 거부에 직접 노출 |
| 서버사이드 GTM(sGTM) | GTM 서버 컨테이너 (구글 클라우드·AWS 호스팅) | 마케터 (GUI) | 중간 | 브라우저 차단 우회 |
| 직접 전환 API(CAPI) 호출 | 광고주 백엔드 → 채널 그래프 API | 개발자 | 높음 | 가장 정확, 마케터 의존도 낮음 |
실무에서는 셋 중 하나만 쓰는 게 아니라 클라이언트 사이드를 기본으로 두고 서버사이드(sGTM 또는 직접 CAPI)를 함께 운영하는 하이브리드 구성이 일반적입니다. 클라이언트 신호로 잡히는 사용자는 그대로 잡고, 잃은 신호를 서버사이드로 보강하는 식입니다.
서버사이드의 두 표준이 메타의 전환 API(CAPI, Conversions API)와 구글의 향상된 전환(Enhanced Conversions)입니다. CAPI는 메타 픽셀을 서버사이드로 보완하는 방식으로, iOS ATT 이후 손실된 데이터를 메우는 핵심 도구가 됐습니다. 클라이언트 측 메타 픽셀과 서버 측 CAPI를 함께 쓰는 하이브리드 구성이면 손실됐던 전환의 15~40%를 회복한다는 보고가 일반적입니다. 향상된 전환은 사용자 퍼스트파티 데이터(이메일·전화번호 해시값)를 구글에 전달해, 쿠키 없이도 정확한 어트리뷰션을 가능하게 합니다.
2) 퍼스트파티 데이터 해싱
이 두 인프라가 작동하려면 퍼스트파티 데이터의 해싱이 핵심입니다. 광고주는 이메일·전화·이름·주소 같은 사용자 정보를 SHA-256으로 해시해서 채널에 보냅니다. 해시된 값은 원본을 복원할 수 없지만, 채널 쪽에서 같은 방식으로 해시한 자기 사용자 데이터와 매칭이 가능합니다.
(1) 퍼스트파티 데이터란
광고주가 자기 사용자에게서 직접 수집한 데이터입니다. 회원가입 시 받는 이메일·전화번호·이름·주소, 구매 내역, 앱 안 행동 기록 같은 것들입니다. 광고주가 직접 소유한 데이터라 쿠키 차단·iOS ATT 같은 외부 추적 환경 변화에 영향을 받지 않습니다. 쿠키리스 시대에 광고 측정의 무게중심이 외부 식별자(쿠키·IDFA)에서 광고주가 직접 가진 퍼스트파티 데이터로 옮겨가고 있는 게 큰 흐름입니다.
용어 위계를 정리하면 다음과 같습니다.
| 데이터 종류 | 출처 | 예시 | 외부 환경 영향 |
|---|---|---|---|
| 퍼스트파티(1st-party) | 광고주가 직접 수집 | 회원 이메일, 구매 내역 | 적음 |
| 세컨드파티(2nd-party) | 파트너에게서 받음 | 제휴사 사용자 데이터 | 중간 |
| 서드파티(3rd-party) | 데이터 브로커에게서 구매 | 외부 쿠키 기반 행동 데이터 | 큼 (쿠키 차단으로 거의 소멸) |
(2) 해싱이란
해싱은 입력 데이터를 고정 길이의 문자열로 변환하는 단방향 수학 연산입니다. SHA-256이 광고 업계 표준 알고리즘입니다.
입력: user@example.com
SHA-256 해시값: b4c9a289323b21a01c3e940f150eb9b8c542587f1abfd8f0e1cc1ffc5e475514
세 가지 성질이 매칭에 쓰일 수 있는 자리를 만듭니다.
| 성질 | 의미 |
|---|---|
| 결정성 | 같은 입력은 언제나 같은 해시값을 만듦 |
| 단방향 | 해시값에서 원본 데이터로 되돌릴 수 없음 |
| 충돌 회피 | 입력이 조금만 달라도 해시값이 완전히 달라짐 |
(3) 둘을 결합하면: 매칭 메커니즘
광고주 측과 채널 측이 같은 해시 알고리즘으로 자기 데이터를 변환한 뒤, 결과 해시값만 주고받아 같은 사용자인지 확인합니다. 원본 이메일·전화번호는 어느 쪽에서도 평문으로 흐르지 않습니다.
[광고주 서버] [채널 서버]
이메일: user@example.com 이메일: user@example.com
│ │
▼ SHA-256 ▼ SHA-256
6e3a8b...c4d2 6e3a8b...c4d2
│ │
└────────────── 해시값 매칭 ─────────────────┘
(PII는 평문으로 흐르지 않음, 매칭만 가능)
광고주는 “user@example.com이 우리 사이트에서 결제했다”라고 보내는 게 아니라, “이메일 해시값 6e3a8b…c4d2 사용자가 결제했다”고 보냅니다. 채널은 자기 사용자 중 같은 해시값을 가진 사용자가 있는지 찾고, 있으면 “그 사용자가 우리 광고를 봤다”는 자기 데이터와 결합해 어트리뷰션을 완성합니다. 양쪽 모두 평문 이메일을 노출하지 않은 채 매칭만 성립하는 구조라, 결정성·단방향·충돌 회피 세 성질이 모두 필요한 자리입니다.
GTM의 CAPI 템플릿이 이 해싱을 자동 처리해 마케터가 직접 코드를 짜지 않아도 됩니다.
3) 이벤트 중복 제거
CAPI나 향상된 전환을 도입한 광고주가 가장 먼저 부딪히는 문제가 이중 카운트입니다. 클라이언트 사이드 픽셀과 서버사이드 인프라를 함께 운영하면 같은 사용자의 같은 전환이 두 경로로 동시에 채널에 전달돼, 한 건이 두 건으로 잡힙니다.
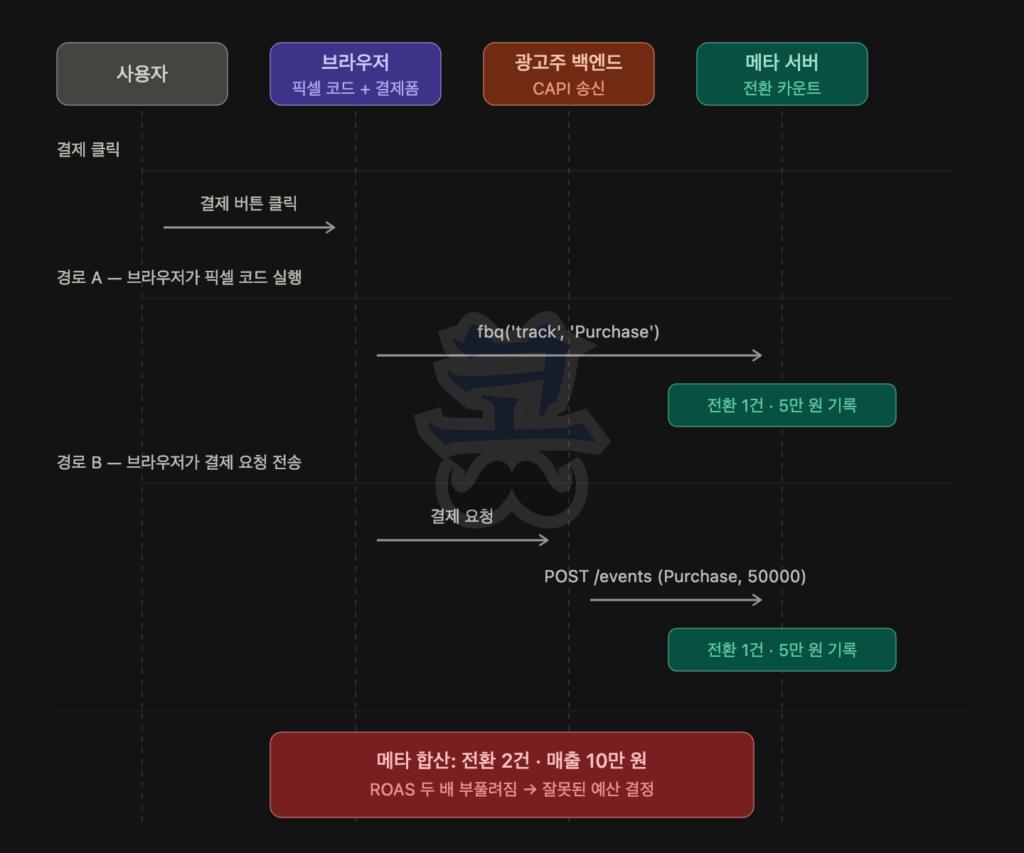
이 상태로 두면 ROAS가 두 배로 부풀려져 잘못된 예산 결정을 부르는 자리입니다.
(1) 해결: event_id 기반 중복 제거
이중 카운트를 막으려면 광고주의 백엔드가 한 곳에서 event_id(주문 ID)를 생성한 뒤, 그 같은 값을 클라이언트 경로와 서버 경로 양쪽에 전달해야 합니다. 보통 광고주 사이트의 데이터 레이어(data layer)를 매개로 합니다.
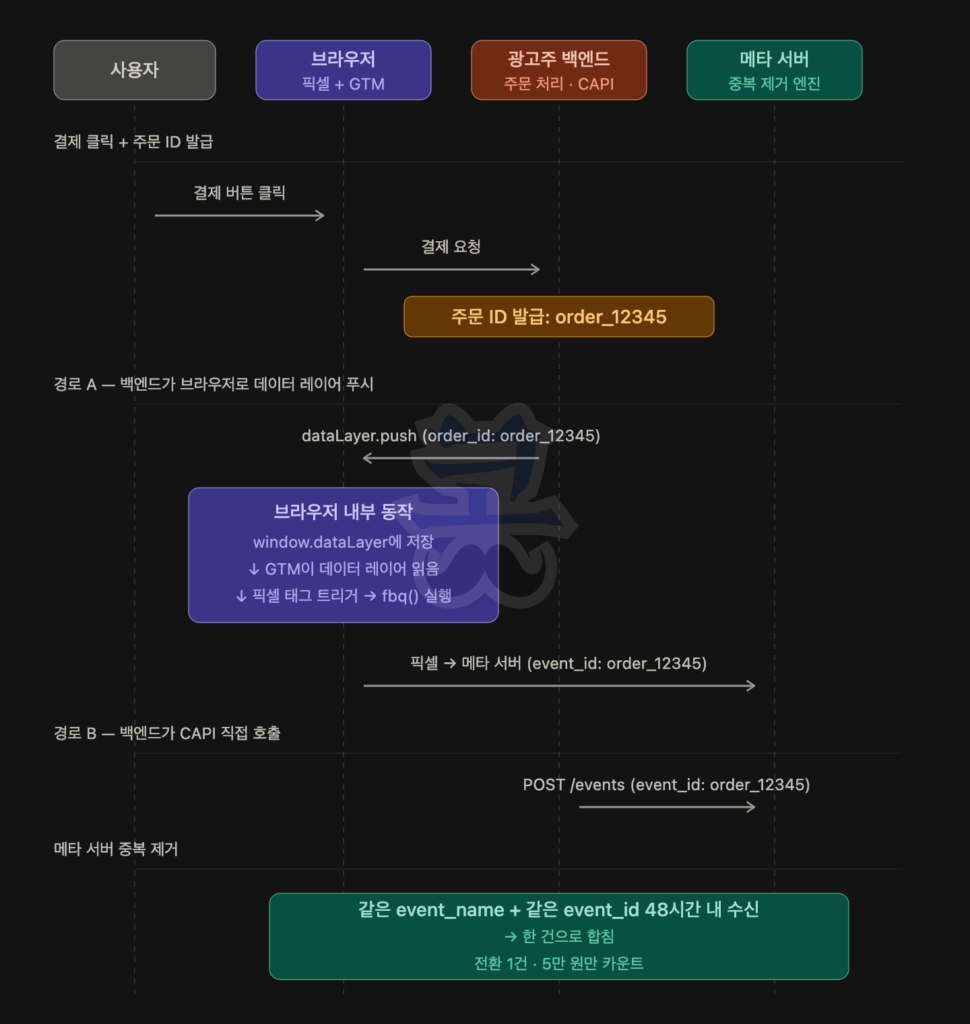
[사용자 결제] → [광고주 백엔드: 주문 처리, order_12345 생성]
│
│ 같은 백엔드가 두 경로를 동시에 시작
│
├──→ [경로 1: 클라이언트 픽셀]
│ 백엔드가 주문 완료 페이지 HTML 렌더
│ (<script>에 order_12345 값 주입)
│ ↓
│ 사용자 브라우저가 페이지 로딩
│ ↓
│ window.dataLayer.push({
│ event: 'purchase',
│ order_id: 'order_12345'
│ })
│ ↓
│ GTM이 dataLayer 읽음
│ ↓
│ fbq('track', 'Purchase', {
│ event_id: 'order_12345'
│ })
│ ↓
│ [메타 서버]
│
└──→ [경로 2: 서버 CAPI]
백엔드가 메타 Graph API로 HTTP POST 직통
POST /events {
event_id: 'order_12345',
user_data: {em: 'sha256(이메일)', ...}
}
(브라우저·데이터 레이어 안 거침)
↓
[메타 서버]
핵심은 event_id가 양쪽 경로에서 같은 출처(광고주 백엔드의 주문 ID)로부터 와야 한다는 점입니다. 클라이언트 픽셀이 자체적으로 랜덤 event_id를 만들고 서버는 주문 ID를 쓴다면, 두 신호의 event_id가 달라 중복 제거가 실패합니다.
데이터 레이어를 매개로 두 경로를 동기화하는 게 GTM 환경의 표준 패턴이고, 광고주 백엔드가 주문 ID를 한 번 만들어 양쪽에 같은 값으로 분배하는 게 구현의 핵심입니다.
event_id가 다르거나 event_name이 다르면 중복 제거가 실패해 두 번 카운트됩니다. 대소문자까지 정확히 일치해야 해서 광고주가 CAPI 도입 초기에 가장 자주 디버깅하는 자리이기도 합니다.
(2) 데이터 레이어 푸시의 실제 모습
데이터 레이어 푸시는 광고주의 주문 완료 페이지에서 일어나는 자바스크립트 동작입니다. 백엔드가 주문을 처리한 뒤 사용자를 주문 완료 페이지로 보낼 때, 그 페이지 HTML 안에 <script> 태그로 주문 정보를 주입합니다.
서버사이드 템플릿(Shopify의 Liquid, WordPress의 PHP, 자체 백엔드 템플릿 등) 예시:
<!-- 주문 완료 페이지: /order/complete -->
<!-- 백엔드 템플릿이 실제 주문 데이터로 변수 자리를 렌더해 응답 -->
<script>
window.dataLayer = window.dataLayer || [];
window.dataLayer.push({
event: 'purchase',
order_id: 'order_12345', // 백엔드가 실제 주문 ID로 채움
value: 50000, // 백엔드가 실제 결제 금액으로 채움
currency: 'KRW',
email_hash: 'b4c9...' // 백엔드가 사용자 이메일을 SHA-256 해시한 값
});
</script>
브라우저가 이 페이지를 로딩하면 다음 흐름이 일어납니다.
[1] 사용자 브라우저: 주문 완료 페이지 HTML 다운로드
│
▼
[2] <script> 실행 → window.dataLayer 배열에 주문 객체 추가
│
▼
[3] 페이지에 미리 심어둔 GTM 컨테이너 스크립트가 dataLayer 변화 감지
│
▼
[4] GTM이 event: 'purchase'에 매핑된 메타 픽셀 태그에 전달
fbq('track', 'Purchase', {
event_id: dataLayer의 order_id, ← order_12345
value: dataLayer의 value
})
│
▼
[5] 신호가 메타 서버로 전송
왜 직접 픽셀을 호출하지 않고 데이터 레이어를 거치나
광고주 백엔드가 픽셀을 직접 호출하는 코드를 페이지에 심으면 매체가 늘어날 때마다 백엔드 코드를 고쳐야 합니다. 데이터 레이어는 광고주 백엔드와 매체 픽셀 사이의 다리 역할을 합니다. 백엔드는 주문 정보를 데이터 레이어에 한 번만 올려두고, 메타 픽셀·구글 애즈 픽셀·틱톡 픽셀 모두 GTM 트리거를 통해 같은 데이터 레이어를 읽어 갑니다. 매체를 추가하거나 바꿀 때 GTM에서 태그만 추가·수정하면 되고 백엔드 코드는 손대지 않아도 되는 게 데이터 레이어 패턴의 핵심 장점입니다.
서버사이드 CAPI 호출도 같은 백엔드의 주문 데이터를 출처로 씁니다. 데이터 레이어에 올린 같은 order_12345·이메일 해시값을 백엔드가 자기 컨텍스트에서 그대로 CAPI로 보내, 두 경로의 event_id가 자연스럽게 일치합니다.
(3) event_id와 해시값이 둘 다 필요한 이유
| 차원 | event_id | 해시값 매칭 |
|---|---|---|
| 푸는 문제 | 같은 전환의 이중 카운트 방지 | 그 전환을 한 사용자가 누구인지 식별 |
| 매체사가 보는 것 | “같은 전환 신호가 두 번 들어왔는지” | “이 전환자가 우리 광고를 본 사용자 중 누구인지” |
| 없으면 생기는 문제 | ROAS가 두 배로 부풀려짐 | 매체사가 누구의 전환인지 몰라 캠페인에 매기지 못함 |
- event_id: 같은 전환임을 알리는 라벨 → 이중 카운트 방지
- 해시 매칭: 그 전환을 한 사용자를 식별하는 신호 → 어트리뷰션
- 둘 다 보내야 “한 번만 카운트되고 + 정확한 캠페인에 매겨지는” 결과가 나옴
메타가 CAPI로 받은 “order_12345 결제가 일어났다”는 신호만으로 할 수 있는 일과 못 하는 일을 나눠 보면 분명해집니다.
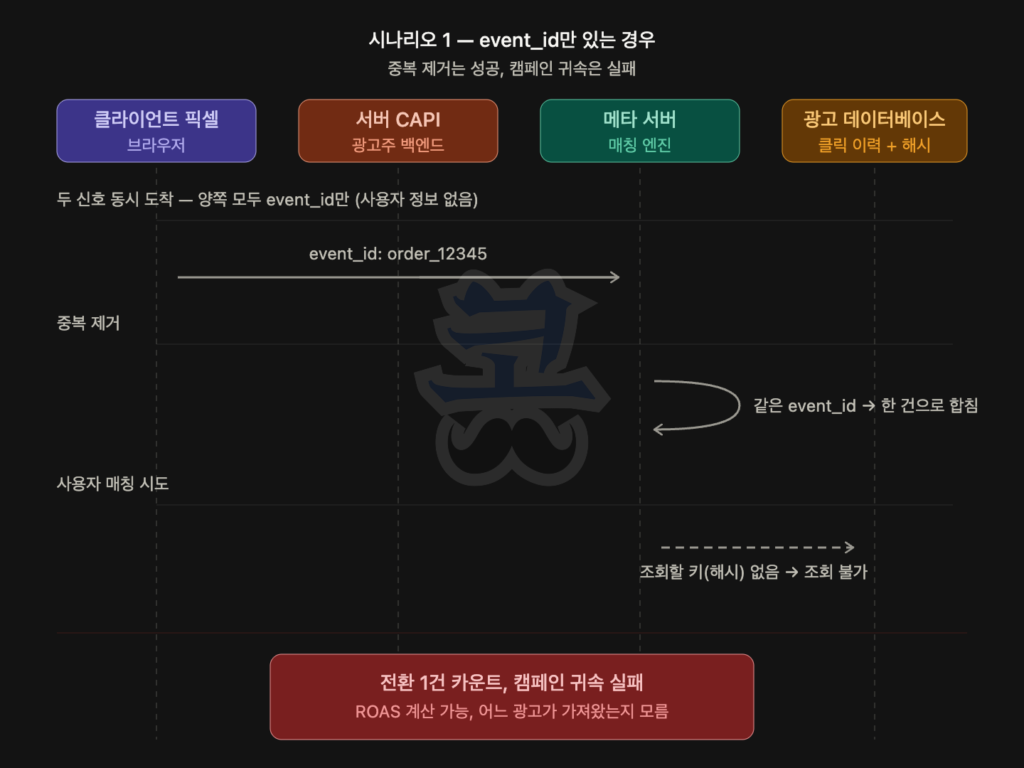
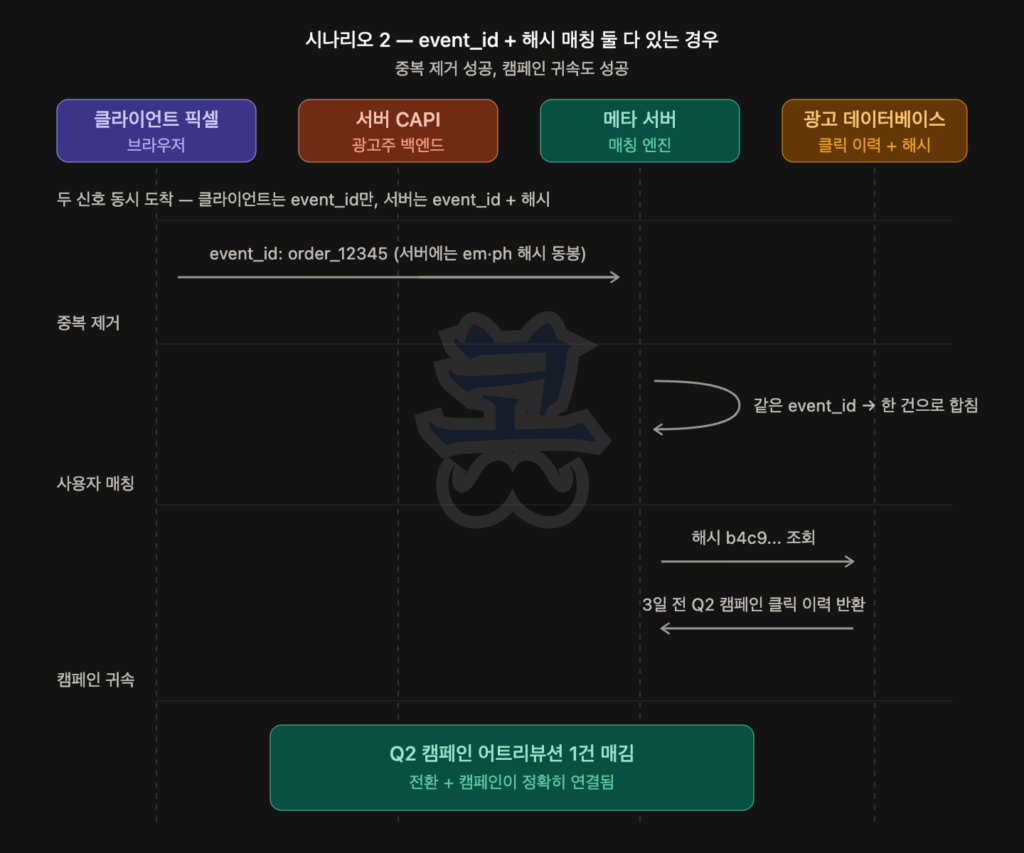
쿠키 시대에는 메타의 fbp 쿠키가 사용자 식별을 자동으로 처리했습니다. 사용자가 메타에 로그인한 브라우저로 광고주 사이트에 들어오면 fbp 쿠키가 자동으로 붙어, 메타가 “이 사람이 우리 사용자다”라고 즉시 알아봤습니다. 광고주가 별도로 사용자 식별 정보를 보낼 필요가 없었습니다.
쿠키 차단·iOS ATT 이후로 fbp 쿠키가 약해지면서 메타가 자체적으로 사용자를 식별할 수 있는 길이 좁아졌고, 광고주 백엔드가 직접 가진 이메일·전화번호 해시값을 함께 보내는 게 매칭의 핵심 길이 됐습니다. EMQ 점수가 높을수록 매칭 성공률이 높아져 어트리뷰션된 전환 수가 늘어나는 것도 이 때문입니다.
4) EMQ: 매칭 품질 점수의 메커니즘
서버사이드 데이터의 품질은 EMQ(Event Match Quality)라는 0~10 척도로 측정됩니다. “데이터를 보냈다”는 사실이 아니라 “보낸 데이터가 매체사의 자기 사용자 데이터베이스와 매칭하는 데 얼마나 유용했는가”를 점수로 매긴 것입니다. 광고주가 보낸 사용자 식별자 종류와 품질에 따라 결정됩니다.
| 식별자 | 매칭 기여도 | 비고 |
|---|---|---|
| 이메일 (SHA-256 해시) | 높음 | 가장 정확 |
| 전화번호 (해시) | 높음 | 이메일과 함께 보내면 효과 배가 됨 |
| 외부 ID(광고주 내부 user ID) | 높음 | 메타와 한 번 매핑해두면 다음부터 즉시 매칭 |
| 클릭 ID(fbc 쿠키) | 높음 | 메타 광고 클릭한 사용자에게만 존재 |
| 브라우저 ID(fbp 쿠키) | 중간 | 메타 픽셀이 자동 생성 |
| 이름·주소 (해시) | 중간 | 보조 신호 |
| IP 주소 + User-Agent | 낮음 | 부정확한 마지막 보루 |
| 도시·국가 | 낮음 | 보조 신호 |
CAPI가 EMQ를 끌어올리는 핵심 이유는 광고주 백엔드가 클라이언트 픽셀이 못 잡는 강한 식별자를 한 번에 보낼 수 있기 때문입니다. 클라이언트 픽셀은 브라우저에서 잡을 수 있는 fbc·fbp 쿠키 정도만 보내지만, 광고주 백엔드는 회원 가입 시 받은 이메일·전화번호와 사용자 ID까지 모두 알고 있어 같은 전환에 더 많은 식별자를 붙여 보낼 수 있습니다.
| EMQ 점수 | 매칭 신호 수준 | 어트리뷰션 결과 |
|---|---|---|
| 6.0 미만 | 매칭에 쓸 수 있는 식별자 부족 (예: IP만, fbp만) | 베이스라인 |
| 6.0~8.0 | 적정 매칭 (이메일 또는 전화 + 보조 신호) | 베이스라인 +5~15% |
| 8.0 이상 | 다중 강한 신호 (이메일 + 전화 + 외부 ID) | 베이스라인 +15~25% |
(1) 왜 EMQ가 운영 변수인가
같은 광고비를 써도 EMQ에 따라 잡히는 전환 수가 15~25% 차이 난다는 건 ROAS 보고가 그만큼 차이 난다는 뜻이고, 이 차이가 그대로 매체별 예산 배분 결정으로 이어집니다. EMQ를 8 이상으로 끌어올리는 운영 작업이 곧 광고비 효율을 끌어올리는 작업이라, EMQ는 단순한 측정 지표가 아니라 광고주가 직접 손볼 수 있는 운영 변수입니다.
| 작업 | 효과 |
|---|---|
| 회원 가입 시 이메일·전화번호 둘 다 수집 | 두 식별자를 함께 보낼 수 있음 |
| 클라이언트 픽셀의 fbc·fbp 쿠키를 백엔드로 전달 | 서버사이드 신호에 클릭 ID 추가 |
| 외부 ID(광고주 내부 user ID)를 메타에 한 번 매핑해두기 | 다음 전환부터 외부 ID로 즉시 매칭 |
| 해시값을 SHA-256 표준대로 정규화(소문자·공백 제거) | 같은 사용자인데 매칭 실패하는 자리 차단 |
광고주가 EMQ 점수를 메타 광고 관리자에서 일·주 단위로 모니터링하면서 위 자리들을 손보면, 같은 광고비로 보고되는 전환이 늘어납니다.
(2) 사용자마다 메타에 등록한 식별자가 다름
같은 사용자라도 메타에 가입할 때 이메일로만 등록했을 수도, 전화번호로만 등록했을 수도, 둘 다 등록했을 수도 있습니다. 광고주가 이메일만 보내면 메타에 전화로만 가입한 사용자는 매칭이 실패합니다. 둘 다 보내면 둘 중 하나라도 맞는 자리가 늘어 매칭 성공률 자체가 올라갑니다.
[광고주가 가진 사용자 100명 → 메타와 매칭]
이메일만 보낼 때: 메타에 이메일 등록한 60명만 매칭
전화만 보낼 때: 메타에 전화 등록한 70명만 매칭
둘 다 보낼 때: 이메일 또는 전화 중 하나라도 등록한 90명 매칭
(합집합으로 매칭 풀이 넓어짐)
(3) 둘 다 맞으면 EMQ 점수가 더 올라감
매칭은 하나만 맞아도 성립하지만, 메타는 더 많은 식별자가 일치할수록 “같은 사용자가 맞다”는 신뢰도를 높게 매깁니다. 신뢰도가 높을수록 EMQ 점수가 오르고, 어트리뷰션 정확도와 광고비 효율이 같이 올라갑니다.
| 매칭된 식별자 | 매칭 신뢰도 | EMQ 점수 영향 |
|---|---|---|
| 이메일 1개만 | 적정 | 6~7 |
| 전화 1개만 | 적정 | 6~7 |
| 이메일 + 전화 동시 매칭 | 높음 | 7~8 |
| 이메일 + 전화 + 외부 ID | 매우 높음 | 8 이상 |
(4) 잘못된 매칭(false match) 차단
이메일 하나만으로 매칭하면 같은 이메일을 공유하는 다른 사람(예: 가족 공용 이메일, 회사 대표 메일)이 잘못 매칭될 위험이 있습니다. 이메일 + 전화 조합으로 검증하면 두 식별자가 같은 사용자에 묶여 있는지 교차 확인할 수 있어 잘못된 매칭을 줄입니다.
| 자리 | 효과 |
|---|---|
| 매칭 풀(매칭 성공률) | 두 식별자의 합집합으로 넓어짐 |
| 매칭 신뢰도(EMQ) | 둘 다 일치하면 점수 상승 |
| 매칭 정확도 | 잘못된 매칭 위험 감소 |
이 세 가지가 동시에 일어나기 때문에 “둘 다 보내라”가 표준 권장이 됩니다. 둘 중 하나만 맞으면 되는 OR 매칭에 그치지 않고, 둘 다 보내야 매칭 풀과 신뢰도와 정확도를 한 번에 끌어올릴 수 있습니다.
쿠키 차단과 ATT가 만든 신호 손실 자리에 대한 웹의 답은 두 층의 인프라로 정리됐습니다. 클라이언트 사이드 픽셀이 잡는 신호 위에 서버사이드 인프라가 손실분을 보강하는 하이브리드 구성이 표준이 됐고, EMQ 점수가 매체사 매칭의 품질을 나타내는 지표로 자리 잡았습니다. 같은 광고비를 써도 EMQ가 8 이상인 광고주와 6 미만인 광고주의 보고된 ROAS가 15~25% 차이 나는 환경에서, 신호 인프라 운영 자체가 광고비 효율의 변수가 됐습니다.
다만 이 인프라가 풀어주는 자리는 “광고를 본 사용자가 매출로 이어졌나”라는 질문까지입니다. “그 사용자는 광고를 안 봤어도 살 사람이었나”, “광고비를 30% 늘리면 매출이 얼마나 더 늘까” 같은 질문은 어트리뷰션·픽셀·서버사이드를 모두 갖춰도 답하지 못합니다. 다음 편(7-3)은 이 질문들에 답하는 고급 측정 도구(증분 효과, 브랜드 리프트, 미디어 믹스 모델링)와, 매체사가 자기 광고에 매긴 점수를 다시 검증하는 외부 인프라(광고 검증 사업자, 사기 검출, 데이터 클린룸)를 다룹니다.
프로그래매틱 광고 시리즈
(2) 광고가 거래되는 시장: 오픈 웹, 월드 가든, 리테일 미디어
(4) RTB와 헤더 비딩의 메커니즘: 100ms 안의 경매
(5) 데이터와 식별자: 광고가 “나에게 맞는 광고”가 되는 원리
(6) 크리에이티브와 캠페인 운영: 광고를 만들고 올리기
(7)-① 측정·어트리뷰션·검증: 광고비와 성과 측정의 기본