
분석가가 아침에 메일을 한 통 받습니다. 첨부에 CSV 파일이 한 장 붙어 있고, 본문에는 “이번 분기 회원가입 분석에 쓸 데이터입니다”라는 두 줄짜리 문장이 적혀 있습니다. 파일을 열면 컬럼명이 cust_st, pmt_dt, prd_v, mlst로 들어가 있습니다. 한 시간을 들여 짐작으로 의미를 채워 보다가 결국 작성자에게 메일을 보냅니다. 답이 오는 데 몇 시간이 걸리고, 답이 와도 빠진 컬럼이 또 보입니다. 분석을 시작하기도 전에 한 주가 지나갑니다.
1. 데이터가 자기 자신을 설명하지 못할 때
위의 메일 사례는 단순히 문서화를 한다고 해서 풀리는 문제가 아닙니다. 컬럼명을 풀어 적은 문서를 어딘가에 둔다고 해서 같은 일이 반복되지 않으리라는 보장이 없습니다. 다음 분기에 새로운 데이터셋이 오면, 그 문서가 어디에 있는지를 다시 찾아다니게 됩니다. 문서가 있어도 데이터셋 자체에 연결되어 있지 않으면, 사용자는 데이터를 열어 놓고 슬랙이나 컨플루언스를 뒤져서 정의를 찾고, 다시 데이터로 돌아오는 과정을 매번 반복하게 됩니다.
문제는 데이터 자체가 자기 자신을 설명하지 못하는 구조에 있습니다. CSV 파일은 컬럼 값만 가지고 있고, 그 값이 무엇을 의미하는지·어떤 형식인지·누가 만들었는지·왜 만들어졌는지를 담지 못합니다. 사용자는 그 빈자리를 가정으로 메우거나, 다른 사람을 찾아 묻거나, 위키 검색을 시작합니다. 모든 분석 작업이 이 빈자리 메우기에서 시작합니다.
개념에 대한 합의가 내려지면 나오는 질문은 바로 다음과 같습니다.
합의된 정의를 어디에 둘 것인가?
사람 머릿속에 두면 그 사람이 떠나는 순간 사라지고, 위키에 적어 두면 데이터셋과 따로 놀게 됩니다. 정의와 데이터를 하나의 단위로 묶어서 관리할 수 있는 그릇이 필요합니다. 그 그릇이 데이터 프로덕트입니다.
2. 데이터 프로덕트: 쟁여두기만 하는 자산에서 적극적으로 사용하는 제품으로
데이터를 자산으로만 보는 시각은 데이터를 ‘모으는 데’에 집중합니다. 데이터를 일종의 제품으로 보는 시각은 데이터를 쓰는 사용자의 경험을 측정합니다. 회원가입 폼의 사용성을 측정하듯, 데이터에도 비슷한 척도를 적용할 수 있습니다.
같은 데이터셋을 두고도 두 시각은 묻는 질문이 다르고, 성공을 판단하는 기준도 다릅니다.
| 기준 | 자산 시각 | 프로덕트 시각 |
|---|---|---|
| 성공의 정의 | 데이터를 빠짐없이 수집하고 안전하게 저장했는가 | 사용자가 이 데이터로 문제를 풀 수 있는가 |
| 소요 시간 | 측정 대상이 아님 | 사용자가 원하는 데이터를 찾고 의미를 이해하는 데 걸리는 시간 |
| 접근 경로 | 측정 대상이 아님 | 정의, 구조, 맥락을 확인하려고 오가야 하는 시스템 수 |
| 실패 신호 | 수집 누락, 저장 장애 | 데이터를 못 찾아 분석을 포기하거나, 잘못 해석해서 엉뚱한 결과가 나오는 경우 |
데이터를 제품과 같이 다루겠다는 결정이 이뤄졌다면, 그다음에는 구체적인 구성 방법에 대한 질문이 나와야 합니다. 하나의 데이터 프로덕트 안에 무엇이 담겨야 사용자가 다른 시스템을 뒤지지 않고 바로 쓸 수 있을까요?
데이터가 제품으로 사용되려면 데이터, 구조, 의미, 맥락이 갖춰져야 합니다.
| 측면 | 무엇을 담는가 | 빠지면 생기는 일 | 예시 (주문 데이터셋) |
|---|---|---|---|
| 데이터 | 실제 값. 레코드와 이벤트 | 분석할 대상 자체가 없음 | 주문 일시, 구매자 ID, 상품명, 수량, 단가 |
| 구조 | 값의 타입, 형식, 제약 조건, 필수 여부 | 같은 컬럼을 받는 쪽마다 다르게 해석함 | order_date는 ISO 8601, quantity는 1 이상 정수 |
| 의미 | 같은 이름의 여러 뜻 중 구체적으로 어느 쪽인가 | 컬럼명만 보고 추측해서 엉뚱한 결과가 나옴 | region이 배송지인지, 구매자 거주지인지, 매출 권역인지 |
| 맥락 | 누가, 왜, 어디서 만들었는지. 담당자, SLA, 접근 권한, 계보 | 써도 되는 건지 판단할 수 없고, 문제가 생겨도 물어볼 곳이 없음 | 담당 팀은 커머스 데이터팀, SLA는 1시간 이내 갱신 |
네 측면이 한 단위 안에 함께 담겨야 사용자가 다른 시스템을 뒤지지 않고 바로 쓸 수 있습니다. 각 측면이 구체적으로 어떤 모습인지 하나씩 풀어 보겠습니다.
1) 데이터: 정보 그 자체
데이터 프로덕트의 첫 번째 측면은 정보 그 자체입니다. 실제로 분석하고 활용할 레코드와 이벤트가 여기에 해당합니다.
이커머스 주문 데이터셋을 예로 들어 보겠습니다. 아래 표에서 행 하나가 주문 한 건입니다.
| order_date | buyer_id | item_name | quantity | unit_price | channel | region |
|---|---|---|---|---|---|---|
| 1715140800 | U-39201 | BLK-TEE-M | 3 | 29000 | APP | SEL |
| 2024-05-08T10:00:00Z | 39201 | 블랙 반팔 티 M | 3 | 29000 | mobile_app | 서울 |
두 행은 같은 주문을 적은 것일 수도 있고, 다른 주문일 수도 있습니다. 이 표만 봐서는 판단이 안 됩니다. 얼핏 보면 분석을 바로 시작할 수 있을 것 같지만, 컬럼 하나하나를 뜯어 보면 질문부터 쏟아집니다.
| 컬럼 | 한국어 의미 | 예시 값 | 이 값을 보고 드는 질문 |
|---|---|---|---|
| order_date | 주문 일시 | 1715140800 | 유닉스 시간? ISO 8601? 어느 시간대? |
| buyer_id | 구매자 식별자 | U-39201 | 회원 ID? 비회원도 포함? |
| item_name | 상품명 | BLK-TEE-M | 내부 코드? SKU? 사람이 읽는 이름? |
| quantity | 수량 | 3 | 출고 수량? 결제 수량? 반품 차감 후? |
| unit_price | 단가 | 29000 | 원 단위? 부가세 포함? 할인 전? |
| channel | 판매 채널 | APP | 앱/웹/오프라인 구분 기준이 뭔지? |
| region | 지역 | SEL | 배송지? 구매자 거주지? 어떤 코드 체계? |
값은 다 있는데, 그 값이 뭘 가리키는지는 어디에도 안 적혀 있습니다. 분석가 A는 unit_price를 부가세 포함 금액으로, 분석가 B는 부가세 별도 금액으로 놓고 각자 작업합니다. 같은 파일에서 결과가 다릅니다. 데이터만으로는 이 문제가 안 풀립니다.
2) 구조: 값이 따라야 할 형식
두 번째 측면은 각 값이 어떤 형식으로 들어와야 하는지를 정해 놓은 것입니다. 흔히 스키마(schema)라고 부릅니다.
스키마가 정하는 것은 크게 네 가지입니다.
| 스키마가 정하는 것 | 무엇을 결정하는가 | 위 주문 데이터셋 예시 |
|---|---|---|
| 타입(type) | 값이 문자열인지, 숫자인지, 불리언인지, 배열인지 | unit_price는 숫자, item_name은 문자열 |
| 형식(format) | 같은 타입 안에서 어떤 표기법을 따르는가 | order_date는 문자열이되 ISO 8601을 따름 |
| 제약 조건(constraints) | 값의 범위, 길이, 허용 목록 등 | quantity는 1 이상의 정수, channel은 APP/WEB/OFFLINE 중 하나 |
| 필수 여부(required) | 반드시 채워야 하는 필드인지, 비어 있어도 되는 필드인지 | order_date, buyer_id는 필수, region은 선택 |
이 네 가지가 합의되지 않은 채로 데이터가 오가면, 받는 쪽에서 같은 컬럼을 저마다 다르게 해석합니다. order_date에 유닉스 시간이 들어올 수도 있고 ISO 8601이 들어올 수도 있으면, 받는 쪽은 매번 “이번엔 어느 쪽이지?”를 확인해야 합니다. quantity에 0이나 음수가 들어와도 되는지 안 되는지가 안 정해져 있으면, 반품 처리된 주문을 수량 -1로 넣는 팀과 별도 반품 테이블을 쓰는 팀이 같은 데이터셋에서 다른 결과를 뽑습니다.
구조를 잡을 때 한 가지 더 구분해 두면 편한 게 있습니다. 이미 산업 표준이 잡혀 있는 형식과, 우리 조직에서만 쓰는 형식입니다.
| 구분 | 설명 | 예시 | 형식을 누가 정하는가 |
|---|---|---|---|
| 표준 형식 | 산업 전체에서 합의된 형식 | 날짜(ISO 8601), 이메일(RFC 5322), 국가(ISO 3166), 화폐(ISO 4217) | 국제 표준, RFC |
| 조직 고유 형식 | 우리 비즈니스 안에서만 통하는 형식 | 판매 채널 코드, 내부 지역 코드, 자체 상품 분류 | 우리 조직의 합의 |
표준 형식은 그대로 따르면 됩니다. 조직 고유 형식은 우리가 직접 합의를 만들고 적어 둬야 합니다. 이 둘을 구분 없이 섞어 두면, 어디까지가 표준이고 어디부터가 우리끼리의 약속인지 흐려집니다.
3) 의미: 단어의 여러 의미 중 구체적으로 무엇인가
구조까지 잡히면 데이터는 형식을 갖춥니다. 문제는 같은 컬럼명이라도 쓰는 곳에 따라 뜻이 완전히 달라질 수 있다는 점입니다.
앞에서 본 주문 데이터셋의 region 컬럼으로 비교해 보겠습니다. 구조는 “이 필드는 두세 글자짜리 문자열이다”까지 정합니다. 의미는 “이 문자열은 내부 지역 코드이고, SEL은 서울, PUS는 부산을 가리킨다”까지 정합니다. 구조가 그릇의 모양을 정하는 거라면, 의미는 그 안에 뭐가 담겨 있는지를 정하는 겁니다. 하지만 아직 의미는 불분명합니다.
| region이 가리킬 수 있는 의미 | 사용 도메인 | 들어가는 값 예시 |
|---|---|---|
| 구매자 거주 지역 | CRM | SEL, PUS, DGU |
| 배송 목적지 | 물류 시스템 | 서울, 부산, 대구 |
| 매출 집계 권역 | 재무 리포트 | 수도권, 영남권, 충청권 |
| 창고 소재 지역 | 재고 관리 | DC-SEL, DC-PUS |
| 서버 리전 | 인프라 모니터링 | ap-northeast-2, us-east-1 |
다섯 개 모두 짧은 문자열이고, 구조 정의로 보면 거의 같은 모양입니다. 의미가 안 붙어 있으면 사용자는 컬럼명만 보고 추측합니다. 물류 시스템의 region을 매출 집계 권역으로 잘못 읽으면, 서울 배송 건이 수도권 매출에 두 번 잡히는 식의 오류가 생깁니다.
의미를 데이터에 붙이는 방법은 여러 가지가 있고, 상황에 따라 조합해서 씁니다.
| 방법 | 뭘 하는 건가 | 예시 | 언제 쓰는가 |
|---|---|---|---|
| 필드 어노테이션 | 필드마다 설명과 예시 값을 직접 적어 둠 | JSON Schema의 description에 “배송 목적지 지역 코드”라고 기재, examples에 SEL, PUS 기재 | 모든 경우에 기본으로 붙임 |
| 표준 코드 체계 연결 | 값이 어떤 코드 체계를 따르는지 명시 | “이 필드는 ISO 3166 국가 코드를 따른다”, “행정표준코드를 따른다” | 산업 표준이 있는 필드 |
| 조직 내부 어휘 사전 | 조직에서만 쓰는 용어의 정의를 한곳에 모아 관리 | 사내 데이터 사전에 “region: 주문 데이터에서는 배송 목적지, CRM에서는 구매자 거주지”로 등록 | 같은 용어가 부서마다 다른 뜻으로 쓰일 때 |
세 방법은 배타적이지 않습니다. 필드 어노테이션은 어떤 데이터 프로덕트든 기본으로 붙이고, 표준이 있는 필드는 코드 체계를 연결하고, 조직 안에서 같은 단어가 여러 뜻으로 쓰이는 경우에는 어휘 사전으로 관리합니다.
4) 맥락(Why, Where, Who): 데이터 바깥의 정보
데이터, 구조, 의미가 다 갖춰져도 한 가지가 더 빠지면 실무에서 쓰기 어렵습니다. 이 데이터를 누가, 왜, 어디서 만들었는지입니다. 데이터 자체에 들어가는 값은 아니지만, 그 데이터를 안전하게 쓰려면 반드시 따라와야 하는 정보입니다.
맥락은 왜, 어디서, 누가에 대한 세 가지 질문으로 나뉩니다.
| 질문 | 뭘 묻는가 | 이게 빠지면 생기는 일 | 어디에 기록하는가 |
|---|---|---|---|
| 왜(Why) | 이 데이터는 왜 만들어졌는가, 어떤 문제를 푸는가 | 데이터가 존재하는 이유를 아무도 설명 못 함. 비슷한 데이터셋이 부서마다 따로 만들어짐 | 데이터 프로덕트 스펙 문서, 카탈로그의 설명 필드 |
| 어디서(Where) | 어디서 찾을 수 있는가, 원본은 어디서 흘러온 건가 | 수치가 이상해도 어디서부터 잘못된 건지 추적이 안 됨 | 데이터 카탈로그의 위치 정보, 계보(lineage) 도구 |
| 누가(Who) | 담당자가 누구인가, 접근 권한과 SLA는 어떤가 | 장애가 나도 누구한테 물어야 하는지 모르고, 써도 되는 건지 판단할 수 없음 | 스키마의 owner 필드, 접근 통제 시스템 |
세 질문에 답이 없는 데이터는 방치된 데이터가 됩니다. 분석가가 우연히 발견하더라도 써도 되는 건지, 누구한테 물어야 하는지, 잘못 쓰면 어디에 영향이 가는지 알 수 없습니다.
데이터를 제품으로 다루기 위해 필요한 네 가지 측면 중 맥락이 가장 자주 놓치는 부분입니다. 나머지 셋은 스키마 파일처럼 데이터 가까이에 적히지만, 담당 팀이 누구인지, SLA가 어떤지, 접근 권한은 어떻게 되는지 같은 정보는 지라나 노션에 따로 적혀 있거나 아예 누군가의 머릿속에만 있기 때문입니다. 데이터 프로덕트로 묶을 때는 이 맥락까지 같은 단위 안에 담아야 합니다.
5) 데이터, 구조, 의미, 맥락을 하나로 묶었을 때의 차이
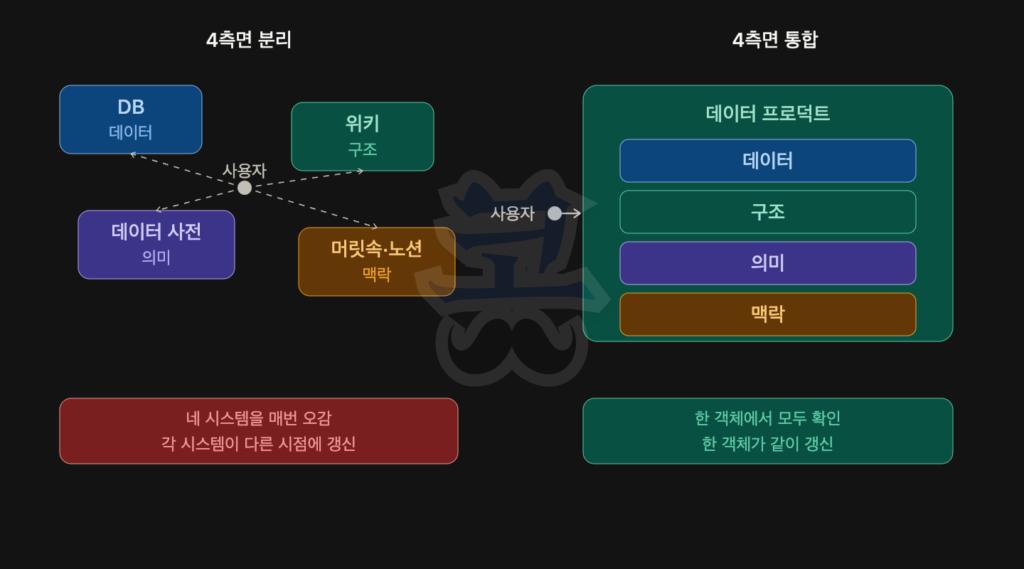
네 측면이 흩어져 있을 때 가장 흔하게 생기는 문제는 정합성입니다. 키에 적힌 구조 설명은 3개월 전 버전이고, 실제 데이터는 지난달에 컬럼이 추가됐고, 데이터 사전은 아예 업데이트가 안 된 상태가 드물지 않습니다. 세 곳의 정보가 서로 다른 시점을 가리키고 있으면, 어느 쪽을 믿어야 하는지부터 확인해야 합니다. 하나로 묶여 있으면 갱신이 한 곳에서 일어나기 때문에 이런 시점 불일치가 줄어듭니다.
재사용성도 큰 차이입니다. 네 측면이 흩어져 있으면 새 프로젝트가 시작될 때마다 “이 데이터 뭐지?”부터 다시 조사합니다. 전임자가 같은 데이터셋으로 이미 분석을 했더라도, 그 과정에서 파악한 구조와 의미와 맥락이 어디에도 남아 있지 않으면 후임자는 똑같은 작업을 처음부터 반복합니다. 하나로 묶여 있으면 한번 정리된 데이터 프로덕트를 다른 팀, 다른 프로젝트에서 그대로 가져다 쓸 수 있습니다.
3. JSON 스키마로 한 문서에 담아 보기
데이터, 구조, 의미, 맥락 네 측면을 하나로 묶겠다고 했을 때, 실무에서 바로 나오는 질문은 “이걸 어디에 어떻게 적느냐”입니다.
위키에 적을 수도 있고, 엑셀로 관리할 수도 있고, ERD를 그릴 수도 있습니다. 문제는 이런 방식들이 대부분 사람이 읽는 문서에 머문다는 점입니다. 사람이 읽을 수 있으면서 동시에 기계도 읽을 수 있는 형식이어야, 문서가 실제 데이터 검증에도 쓰이고 문서와 데이터가 따로 노는 상황을 줄일 수 있습니다.
JSON 스키마는 JSON 데이터의 구조를 정의하고 검증하기 위한 표준입니다. JSON 형태로 작성하기 때문에 사람도 읽을 수 있고, 검증 라이브러리(Python의 jsonschema, JavaScript의 ajv 등)를 통해 실제 데이터가 이 정의에 맞는지 자동으로 확인할 수도 있습니다.
1) JSON 스키마의 키 구조
JSON 스키마에서 쓰는 키들은 역할에 따라 크게 네 그룹으로 나뉩니다.
| 그룹 | 하는 일 | 주요 키 |
|---|---|---|
| 문서 식별 | 이 스키마가 무엇인지, 어떤 버전의 표준을 따르는지 식별 | $schema, $id, title |
| 구조 정의 | 각 필드의 타입, 형식, 제약 조건, 필수 여부를 정의 | type, format, properties, required, minimum, maximum, enum, pattern 등 |
| 의미 설명 | 필드가 구체적으로 뭘 가리키는지를 사람이 읽을 수 있게 적어 둠 | description, examples, default |
| 조직 확장 | 표준 키로 담지 못하는 조직 고유 정보를 붙임 | x-owner, x-updated, x-sla 등 (x- 접두어는 관행) |
각 그룹의 키를 하나씩 보겠습니다.
(1) 문서 식별 키
| 키 | 설명 | 예시 값 |
|---|---|---|
| $schema | 이 문서가 어떤 버전의 JSON 스키마 표준을 따르는지 명시 | “https://json-schema.org/draft/2020-12/schema” |
| $id | 이 스키마의 고유 주소. 다른 스키마에서 참조할 때 이 주소를 씀 | “https://example.com/schemas/order-event.json” |
| title | 이 스키마가 정의하는 대상의 이름 | “이커머스 주문 이벤트” |
(2) 구조 정의 키
| 키 | 설명 | 예시 값 |
|---|---|---|
| type | 값의 데이터 타입. string, integer, number, boolean, array, object, null 중 하나 | “string”, “integer” |
| format | 같은 타입 안에서 따라야 할 세부 형식. 주로 string 타입에 붙음 | “date-time”(ISO 8601), “email”(RFC 5322), “uri” |
| properties | object 타입일 때, 안에 어떤 필드가 있는지를 정의하는 자리 | { “order_date”: { … }, “unit_price”: { … } } |
| required | 반드시 값이 있어야 하는 필드 목록 | [“order_date”, “unit_price”, “region”] |
| minimum / maximum | 숫자 타입의 허용 범위 | minimum: 0이면 음수 불가 |
| minLength / maxLength | 문자열 타입의 길이 범위 | minLength: 2, maxLength: 3이면 두세 글자만 허용 |
| enum | 허용되는 값의 목록. 이 목록에 없는 값은 검증에서 걸림 | [“APP”, “WEB”, “OFFLINE”] |
| pattern | 문자열이 따라야 할 정규식 패턴 | “^[A-Z]{2,3}$”이면 대문자 두세 글자만 허용 |
(3) 의미 설명 키
| 키 | 설명 | 예시 값 |
|---|---|---|
| description | 이 필드가 구체적으로 뭘 가리키는지 사람이 읽을 수 있는 설명 | “부가세 별도, 할인 적용 전 단가 (원)” |
| examples | 실제로 들어오는 값의 예시. 검증에는 쓰이지 않고, 사람의 이해를 도움 | [“2026-05-08T10:00:00Z”] |
| default | 값이 없을 때 기본으로 채워지는 값 | “KRW” |
(4) 조직 확장 키
| 키 | 설명 | 예시 값 |
|---|---|---|
| x-owner | 이 데이터 프로덕트의 담당 팀 | “commerce-data-team” |
| x-updated | 이 스키마가 마지막으로 갱신된 날짜 | “2026-05-01” |
| x-sla | 데이터 갱신 주기에 대한 보장 수준 | “1시간 이내 갱신” |
| x-access | 접근 권한 정보 | “분석팀 이상 조회 가능” |
조직 확장 키는 정해진 목록이 없습니다. 조직에서 필요한 맥락 정보에 맞춰 x- 접두어를 붙여서 자유롭게 추가하면 됩니다. 다만 팀마다 제각각 만들면 의미가 없으므로, 조직 내에서 어떤 확장 키를 쓸지 합의해 두는 게 좋습니다. OpenAPI 스펙에서도 같은 관행을 쓰고 있어서, API를 다뤄 본 사람에게는 익숙한 패턴입니다.
2) 네 측면과의 대응
이 네 그룹이 앞에서 다룬 네 측면과 어떻게 대응되는지 정리하면 다음과 같습니다.
| 측면 | JSON 스키마 그룹 | 대응하는 키 |
|---|---|---|
| 데이터 | 의미 설명 | examples (실제 값의 모습을 보여줌) |
| 구조 | 구조 정의 | type, format, minimum, required, enum 등 |
| 의미 | 의미 설명 | description, title |
| 맥락 | 문서 식별 + 조직 확장 | $id, $schema, x-owner, x-sla 등 |
3) 실제 문서로 보기
앞에서 다룬 주문 데이터셋을 JSON 스키마로 적으면 이렇습니다.
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://example.com/schemas/order-event.json",
"title": "이커머스 주문 이벤트",
"description": "주문 분석을 위한 이벤트 단위 데이터 프로덕트",
"type": "object",
"properties": {
"order_date": {
"type": "string",
"format": "date-time",
"description": "주문 시각, ISO 8601 (UTC)",
"examples": ["2026-05-08T10:00:00Z"]
},
"unit_price": {
"type": "integer",
"minimum": 0,
"description": "부가세 별도, 할인 적용 전 단가 (원)"
},
"region": {
"type": "string",
"description": "배송 목적지 지역 코드, 내부 코드 체계",
"examples": ["SEL", "PUS"],
"pattern": "^[A-Z]{2,3}$"
}
},
"required": ["order_date", "unit_price", "region"],
"x-owner": "commerce-data-team",
"x-updated": "2026-05-01",
"x-sla": "1시간 이내 갱신",
"x-access": "분석팀"
}이 문서 하나에 네 측면이 다 들어가 있습니다. order_date를 예로 보면, type과 format이 구조를, description이 의미를, examples가 실제 데이터의 모습을 보여줍니다. 문서 최상단의 x-owner와 x-sla가 맥락을 담고 있습니다.
이 문서가 그냥 문서로만 존재하는 게 아니라는 점도 중요합니다. 검증 라이브러리를 통해 실제로 들어오는 데이터가 이 정의에 맞는지 자동으로 확인할 수 있습니다. 위키에 적힌 설명과 실제 데이터가 따로 노는 문제가 줄어드는 이유입니다.
JSON 스키마의 더 깊은 내용($ref를 통한 스키마 재사용, 조건부 검증, 중첩 스키마 등)은 별도 JSON 스키마 시리즈에서 다룹니다.
마무리
데이터를 제품으로 다루려면, 데이터 안에 구조, 의미, 맥락이 함께 담겨야 합니다. 네 가지가 흩어져 있으면 사용자는 분석을 시작하기도 전에 정보를 찾아다니느라 시간을 쓰고, 하나로 묶여 있으면 바로 쓸 수 있습니다. JSON 스키마는 이 네 가지를 한 문서에 적을 수 있는 형식 중 하나이고, 문서가 곧 검증 도구가 된다는 점에서 위키나 엑셀과 다릅니다.
데이터 프로덕트 하나가 잘 설계됐다고 해서 조직 전체가 돌아가지는 않습니다. 잘 만든 데이터 프로덕트가 한 사람의 머릿속에만 있으면, 그 사람이 떠나는 순간 다시 사라집니다. 4편에서는 이 설계를 조직 시스템으로 굳히는 단계를 다룹니다.
통합 데이터 전략 시리즈
(1) ‘진단’: 우리 조직은 어디가 정렬되지 않았는가