
1편에서는 RAG가 “비슷한 의미의 페이지를 찾아주는 사서”라는 비유로 RAG의 작동 방식을 따라가 봤습니다. 강력한 도구지만, 사서가 가져다준 페이지 사이의 관계까지는 알려주지 못한다는 한계도 함께 짚었습니다. 그래서 다중 홉 추론, 동음이의어, 다중 소스 종합 같은 질문에서 벡터 RAG는 자주 흔들립니다.
요즘 데이터·AI 업계에서 자주 들리는 단어가 있습니다. 온톨로지(Ontology), 지식 그래프(Knowledge Graph), 그리고 둘과 RAG를 결합한 GraphRAG입니다.
많은 소셜 미디어에서는 “RAG가 죽고 온톨로지와 GraphRAG가 답이다”라는 말이 많이 보입니다. 그런데 실제로 자료들을 따라가 보면, 죽는 게 아니라 보완되는 쪽에 더 가깝습니다. 이 글의 목적은 그 균형을 잡아보는 것입니다.
이 글에서는 네 가지를 차례로 봅니다. 온톨로지가 무엇인지, 지식 그래프는 그것과 어떻게 다른지, 둘과 RAG를 합친 GraphRAG는 어떻게 작동하는지, 그리고 그것을 운영하는 데 어떤 비용이 따르는지 한 번 정리해 보겠습니다.
1. 온톨로지(Ontology): ‘데이터의 의미’를 명시적으로 적어두는 것
한국어로는 ‘온톨로지’ 또는 ‘존재론’으로 옮기지만, 데이터 분야에서 쓸 때는 보통 영어 그대로 부릅니다. 1993년 톰 그루버(Tom Gruber)가 온톨로지에 대해 내린 고전적 정의는 “개념화에 대한 명시적 명세(an explicit specification of a conceptualization)”입니다. 풀어 쓰면, 어떤 도메인에 어떤 사물이 있고, 그것들이 서로 어떻게 연결되는지를 미리 정의해 둔 모델입니다.
온톨리지는 새로운 개념이 아닙니다. 1990년대 말부터 팀 버너스 리(Tim Berners-Lee)가 하고 2001년 사이언티픽 아메리칸(Scientific American) 기고로 널리 알려진 시맨틱 웹(웹 데이터에 기계가 이해할 수 있는 의미를 얹자는 비전) 시대부터 있었고, 한참 잠잠했다가 LLM 시대에 다시 집중되고 있습니다.
AI 에이전트가 의사결정을 하려면 ‘사물 간의 관계와 의미’를 이해해야 하는데, 벡터 임베딩은 의미를 어렴풋이 잡을 뿐 명시적으로는 잡지 못합니다. 그 명시적 의미를 줄 수 있는 게 온톨로지입니다. Year of the Graph Vol. 29 ‘The Ontology issue’는 2026년 들어 마이크로소프트(Microsoft), 팔란티어(Palantir), GenAI 도입 기업, RAG 애플리케이션 빌더까지 모두 온톨로지를 다시 말하기 시작한 흐름을 정리하고 있습니다.
회사 도메인을 예로 들면 온톨로지는 이렇게 생긴 모델입니다.
[Ontology 예시 — 회사 도메인]
┌────────────────────────┐
│ 사람 (Person) │
│ - name │
│ - hire_date │
│ - email │
└───────────┬────────────┘
│ 소속 (belongs_to)
▼
┌────────────────────────┐
│ 부서 (Department) │
│ - name │
│ - cost_center │
│ - head_count │
└───────────┬────────────┘
│ 담당 (owns)
▼
┌────────────────────────┐
│ 프로젝트 (Project) │
│ - name │
│ - start_date │
│ - status │
└────────────────────────┘
핵심은 개체(entity), 속성(attribute), 관계(relation) 세 가지를 명시적으로 적어둔다는 점입니다. ‘사람은 부서에 소속된다’, ‘부서는 프로젝트를 담당한다’ 같은 관계가 이름과 함께 정의되어 있으면, 같은 데이터를 보고도 사람마다 다르게 해석하는 일이 줄어듭니다.
여기서 데이터베이스 스키마와의 차이를 한 번 짚을 만합니다. 스키마는 “데이터를 어떻게 저장할까”의 관점이고, 온톨리지는 “데이터가 무엇을 의미하는가”의 관점입니다. 같은 모양의 테이블 두 개가 있어도 의미는 전혀 다를 수 있고, 그 의미를 명시적으로 적어두는 게 온톨리지의 일입니다. 팔란티어 파운드리(Palantir Foundry)의 온톨로지 문서도 같은 결로, 데이터를 ‘객체·관계·액션 타입’으로 모델링해 데이터 구조와 의미를 분리해서 다룹니다.
2. 지식 그래프(Knowledge Graph): 온톨로지를 데이터로 채운 것
온톨로지가 빈 사전이라면, 지식 그래프(Knowledge Graph)는 그 사전을 따라 실제 데이터를 채워 넣은 백과사전입니다. 노드(node)는 실제 개체이고, 엣지(edge)는 그 개체들 사이의 관계이며, 각 노드와 엣지에 속성이 붙습니다. 사실은 보통 트리플(triple) 단위로 저장됩니다. ‘박지성 — 소속 — 맨체스터 유나이티드’처럼 (주어, 술어, 목적어) 한 줄이 하나의 사실이 됩니다.
다음은 온톨로지를 따라 채워진 작은 지식 그래프의 모양입니다.
[Knowledge Graph 예시 — 회사 도메인]
┌──────────────┐ 소속 ┌──────────────┐ 담당 ┌──────────────┐
│ 김지영 │──────→│ 데이터팀 │──────→│ 추천 시스템 │
│ (Person) │ │ (Department) │ │ (Project) │
└──────┬───────┘ └──────┬───────┘ └──────────────┘
│ │
│ 멘토(mentor_of) │ 협업(collaborates_with)
↓ ↓
┌──────────────┐ ┌──────────────┐
│ 박서준 │ │ 플랫폼팀 │
│ (Person) │ │ (Department) │
└──────────────┘ └──────────────┘
같은 온톨로지를 공유하기 때문에 각 노드의 ‘타입’이 명확합니다. ‘김지영’은 Person이고 ‘데이터팀’은 Department입니다. ‘소속’ 엣지가 무슨 뜻인지도 사전에 정의되어 있어 헷갈릴 일이 적습니다. 이렇게 노드의 타입과 관계가 온톨로지에 정의되어 있다는 점이 지식 그래프가 일반 그래프 데이터베이스와 갈라지는 지점입니다. 일반 그래프 DB는 데이터를 그래프 모양으로 ‘저장’하지만, 지식 그래프는 거기에 더해 데이터의 ‘의미’를 그래프 위에 올립니다.
대표적 사례를 짚어보면 이렇게 정리할 수 있습니다.
| 구분 | 정의 | 비유 | 예시 |
|---|---|---|---|
| 온톨로지 | 도메인의 개체·속성·관계를 명시적으로 정의한 모델 | 빈 사전 | 회사 도메인의 ‘사람-부서-프로젝트’ 모델 |
| 지식 그래프 | 온톨로지를 따라 실제 데이터를 노드와 엣지로 채운 그래프 | 그 사전을 따라 채워진 백과사전 | Google Knowledge Graph, Wikidata, Palantir Foundry 운영 그래프 |
| 일반 그래프 DB | 데이터를 그래프 구조로 저장·질의하는 시스템 | 모눈종이 위에 점과 선을 그린 것 | 소셜 네트워크 친구 관계, 사기 탐지 그래프 |
참고: GraphQL의 ‘Graph’와는 다른 개념입니다.
이름이 비슷해 자주 혼동되지만, 두 ‘Graph’는 가리키는 층이 다릅니다. GraphQL은 API 쿼리 언어로, 저장소가 무엇이든(관계형 DB든 어디든) API가 응답을 그래프 모양으로 돌려주게 해주는 도구입니다. 지식 그래프는 데이터 자체가 노드와 엣지로 저장되고 그 위에서 추론까지 하는 저장소입니다. 한쪽은 응답 모양의 이야기, 다른 쪽은 저장 방식의 이야기입니다.
3. GraphRAG: RAG와 지식 그래프의 결합
벡터 RAG는 비슷한 페이지는 잘 찾지만 페이지 사이의 관계는 모릅니다. 그런데 지식 그래프는 정확히 그 관계를 데이터로 갖고 있습니다. 그 둘을 합친 것이 GraphRAG입니다. 검색 단계에서 벡터 유사도뿐 아니라 지식 그래프의 관계 탐색까지 함께 해 LLM에 더 풍부한 맥락을 넘기는 하이브리드 패턴입니다.
작동 방식을 한 흐름으로 보면 이렇게 정리됩니다.
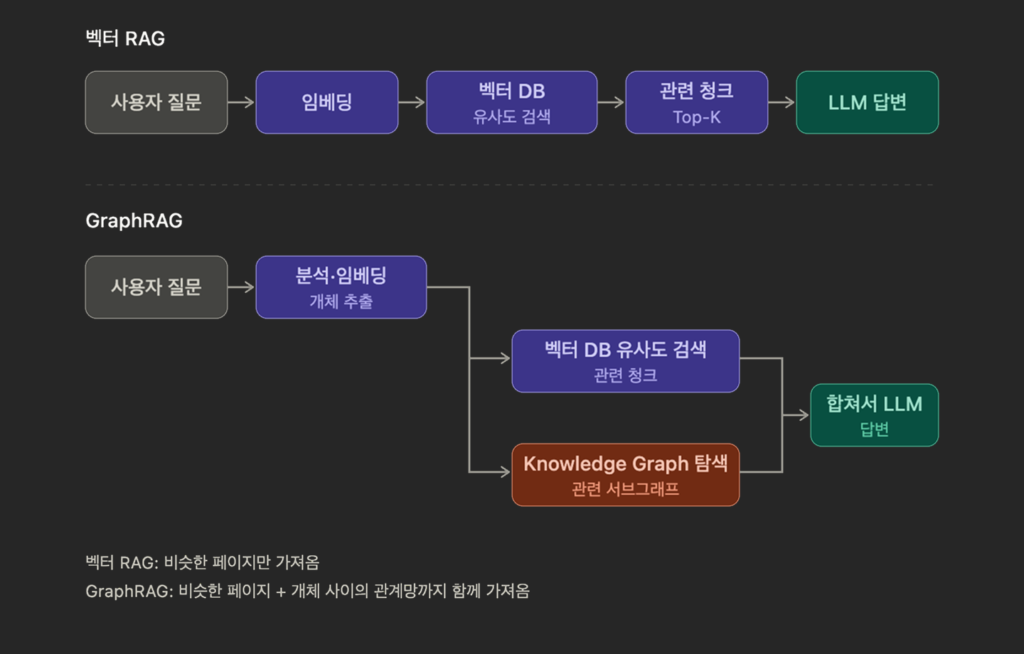
같은 결로, GoodData 블로그는 GraphRAG의 작동을 이렇게 정리합니다.
- 사용자 질의가 들어오면 핵심 개체를 뽑아내고,
- 벡터 검색으로 의미적으로 비슷한 텍스트 청크를 모으는 동시에 지식 그래프에서 그 개체의 이웃과 관계를 함께 가져온 후,
- 둘을 합친 컨텍스트를 LLM에 넘깁니다.
즉, 책을 의미로 찾아주는 사서 옆에, 사물 사이의 관계망까지 아는 사서를 한 명 더 두는 셈입니다.
| RAG의 약점 | GraphRAG가 메우는 방식 |
|---|---|
| 다중 홉 추론: 한 사실에서 다른 사실로 여러 단계를 따라가야 답이 나오는 질문 | 그래프의 노드를 따라 N단계 이동하며 자연스럽게 풀림 |
| 관계의 부재 :비슷한 페이지는 찾지만, 페이지 사이의 연결을 모름 | 엣지가 ‘소속/담당/협업’ 같은 관계를 명시적으로 표현 |
| 동음이의어: ‘Apple’이 회사인지 과일인지 구분이 어려움 | 개체가 온톨로지에서 어떤 타입인지 미리 정해져 있어 모호성이 줄어듦 |
| 다중 소스 종합: 같은 사람·사물에 대한 정보가 여러 문서에 흩어져 있음 | 같은 개체로 모이는 엣지로 자연스럽게 통합 |
Microsoft Research가 공개한 BenchmarkQED와 후속 비교 자료들에서, 다중 홉 질문 정확도는 벡터 RAG가 32%, GraphRAG가 86%까지 벌어졌습니다(정리: TianPan, 2026년 4월). 통신 표준 문서를 다룬 Leeds 대학의 ORAN 벤치마크에서도 하이브리드 GraphRAG가 사실 정확도에서 8%, 컨텍스트 관련성에서 11% 앞섰습니다.
다만 이 숫자만 보고 ‘GraphRAG가 무조건 낫다’고 읽으면 곤란합니다. 단순 사실 조회는 벡터 RAG로 충분히 빠르고 정확합니다. 차이가 벌어지는 건 다중 홉·관계형 질문이 들어올 때입니다. 즉 둘은 대체재가 아니라, 질문 유형에 따라 갈라 쓰는 도구입니다.
4. GraphRAG의 트레이드오프와 운영 비용
여기까지 보면 GraphRAG가 거의 정답처럼 보입니다. 하지만 실제 사례들을 따라가면 그렇게 단순하지 않습니다. 지식 그래프는 만드는 비용도, 유지하는 비용도 큽니다. 이 양면을 같이 봐야 균형이 맞습니다.
1) 먼저 만드는 비용입니다.
- 온톨로지를 직접 설계해야 하고,
- 텍스트에서 개체와 관계를 뽑아야 하고,
- 여러 문서에 흩어진 같은 사람의 다른 표기(‘김지영’, ‘Kim Ji-young’, 사번 등)를 하나의 노드로 묶어내는 ‘엔티티 해소(entity resolution)’까지 거쳐야 합니다.
어느 한 단계도 가볍지 않습니다. Microsoft가 처음 공개한 GraphRAG 방식으로 5GB 규모의 법적 문서를 GPT-4o-mini로 인덱싱할 경우 약 3만 3천 달러가 든다는 추정이 나왔습니다. 이후 LazyGraphRAG나 HippoRAG 같은 변형이 비용을 크게 줄이고 있지만, ‘가볍게 깔아볼 수 있는 도구’와는 결이 다릅니다. CIO 매거진은 Knowledge Graph가 데이터 업계에서 20년 가까이 시도되어 왔지만 운영 환경에 자리 잡는 사례는 여전히 드물다고 정리합니다. 만들고 정착시키는 일 자체가 그만큼 까다롭다는 뜻입니다.
2) 유지 비용도 만만치 않습니다.
새 데이터가 들어올 때 벡터 RAG는 청크를 추가하고 임베딩만 다시 계산하면 끝입니다. 지식 그래프는 여기에
- 그래프 일관성 검증,
- 기존 노드와의 충돌 처리,
- 필요한 경우 엔티티 해소 재실행이 더 붙습니다.
비정형 텍스트를 그래프 노드로 변환하려면 추가적인 스키마 설계와 엔티티 정제가 필요하고, 데이터가 이미 구조화되지 않은 경우 초기 구축이 더 느려진다는 한계도 지적됩니다((Meilisearch의 정리). 문서가 대부분이고 정형 관계 데이터는 거의 없는 환경이라면, 지식 그래프로 모델링할 만한 그림 자체가 잘 안 잡힌다고 합니다.
3) 세 가지 RAG 접근 비교
| 축 | 벡터 RAG | Knowledge Graph 단독 | GraphRAG (하이브리드) |
|---|---|---|---|
| 개발 비용 | 낮음. 임베딩 + 벡터 DB로 빠르게 시작 | 높음. Ontology 설계·개체 추출·엔티티 해소 필요 | 중~높음. 둘을 다 운영해야 함 |
| 유지 비용 | 낮음. 청크 추가·임베딩 갱신 | 높음. 일관성 검증·충돌 처리 | 둘 다 부담 |
| 적합한 데이터 | 비정형 텍스트(문서·매뉴얼) | 정형 관계 데이터(고객·제품·조직) | 둘이 섞인 환경 |
| 적합한 질문 | 단일 사실 조회·요약 | 관계·다중 홉 추론·제약 검사 | 단순 조회와 관계 추론이 모두 필요한 환경 |
| 약점 | 관계 추론·다중 홉에 약함 | 비정형 텍스트 처리에 약함, 운영 부담 큼 | 가장 무거움. ROI 회수 시점 늦어질 수 있음 |
자주 빠지는 함정이 ‘도구가 멋있어 보인다고 처음부터 GraphRAG로 시작하는’ 선택입니다. DEV.to의 분석도 같은 결을 짚습니다. 벡터 RAG로 먼저 가보고, 한계가 분명히 드러나는 시점에 그래프를 얹는 단계적 도입이 안전합니다. 풀어야 할 문제의 무게에 맞춰 도구를 고르는 게 먼저고, 도구의 무게에 문제를 끼워 맞추는 건 나중에 비싼 청구서로 돌아옵니다.
GraphRAG는 화려한 기술입니다. 진짜 봐야 할 건 단어보다 그 뒤에 있는 질문입니다.
우리 도메인의 질문 유형이 무엇이고, 그걸 풀려면 어떤 검색 방식이 필요한가?
의사결정의 출발점은 그래서 늘 같은 자리에 있습니다. 사용자가 우리 시스템에 묻는 질문이
- 단일 사실 조회 위주인지
- 관계 추론이 필요한지
- 다중 소스를 종합해야 하는지
- 동음이의어 해소가 자주 필요한지부터 봅니다.
데이터 형태도 이어서 점검합니다.
- 비정형 텍스트가 대부분인지
- 정형 관계 데이터가 같이 있는지
- 둘이 섞여 있는지
이 두 축이 정해지면 어떤 도구가 어울리는지가 어느 정도 가닥이 잡힙니다.
업계 흐름도 같은 방향을 가리킵니다. Gartner는 2026년 D&A Top Trends에서 GraphRAG를 복잡한 사용 사례의 해법으로 꼽으면서도, 적용 난이도가 만만치 않다는 점을 분명히 짚습니다. Year of the Graph Vol. 30는 같은 흐름 위에서 Neo4j 같은 사업자가 Ontology를 핵심 모델링 단위로 끌어올리는 쪽으로 제품 방향을 잡고 있다고 정리합니다. 화두는 ‘지식 그래프를 도입할 것인가’보다 ‘온톨로지와 의미 계층을 어떻게 자산으로 쌓아둘 것인가’ 쪽으로 옮겨가고 있습니다.
RAG든 GraphRAG든 지식 그래프든, 우리 도메인의 질문에 맞게 짜인 검색·추론 구조가 결국 답이 됩니다.
RAG 시리즈